Olá, pessoal. Neste artigo falarei sobre Web Scraping e criarei um exemplo utilizando Python em conjunto com as bibliotecas Requests e BeautifulSoup. Ao final deste artigo, você será capaz de extrair dados de páginas web estáticas e dinâmicas.
Existem diversas maneiras de se extrair dados da web. A utilização de APIs talvez seja a melhor forma de realizar esse processo mas, e quando o site não fornece esse tipo de recurso, o que fazer? Ai que o Web Scraping entra em “cena”.
O que é Web Scraping?
Essa é uma técnica utilizada para “minerar” dados de web sites, extraindo deles dados relevantes para um determinado assunto, que posteriormente poderá ajudar nas tomadas de decisões. É possível realizar o mesmo processo de maneira manual, mas isso poderia levar muito tempo. Quando se fala sobre Web Scraping a ideia é automatizar a coleta dos dados e transformá-los em uma estrutura legível para se analisar, sendo possível coletar uma grande massa de dados em uma curta fração de tempo.
Benefícios da Scraping
- Obter dados de fontes mais precisas: imagine que você é um empreendedor que deseja saber mais sobre seus concorrentes. Seria uma boa tática poder analisar os dados deles, certo? Usando Web Scraping (Raspagem da Web) você pode conseguir essas informações e obter insights precisos;
- Economizar tempo: com a automatização do processo de Raspagem você ganha tempo realizando o mesmo trabalho que levaria muitas horas e talvez dias para realizar manualmente;
- Novas ideias: com novos dados em mãos, novas análises surgem, descobertas e, consequentemente, ideias. O que antes era desconhecido, após ser estruturado e analisado pode se transformar em um negócio, uma campanha de marketing, entre outros;
- Validar uma ideia de projeto: ao iniciar um projeto, você já se perguntou se aquela ideia era mesmo boa? Com os dados certos em mãos, você terá mais convicção, entendendo se é ou não viável a continuação.
Existem vários ganhos com a Raspagem da Web, esses são apenas alguns que considero importantes.
Agora que você já sabe o que é Web Scraping e alguns de seus benefícios, vamos colocar a mão na massa e criar o nosso próprio “robô minerador”. Utilizarei Tags HTML para navegar e encontrar os dados necessários, considerando que você tenha conhecimento em HTML.
Bibliotecas Utilizadas
- Requests: biblioteca utilizada para execuções de requisições HTTP;
- BeautifulSoup: biblioteca para conversão e extração de dados em arquivo HTML e XML.
As bibliotecas listadas acima serão utilizadas em conjunto, mas cada uma com sua função específica. A Request será utilizada para fazer a requisição e receber o objeto de retorno (Respose). Já a BeautifulSoup, terá o papel de converter o retorno no formato HTML mais legível e realizar a extração dos dados. O site a ser raspado será o elivros.love, que fornece livros digitais de forma gratuita com o intuito de democratizar o acesso à leitura. No site, navegamos até a categoria de livros de aventuras que é o nosso alvo, depois coletaremos as seguintes informações:
- Título do Livro;
- Link para a página específica do livro.
Para fins de estudos, buscaremos somente essas informações, mas você será capaz de fazer muito mais.
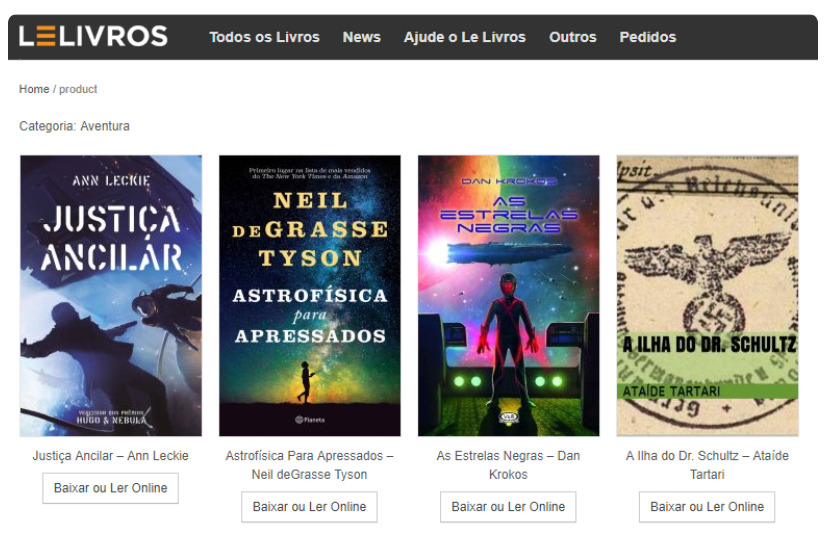
Ambiente de Desenvolvimento
Para desenvolver nosso “robô raspador” eu utilizei a IDE PyCharm mas, você pode usar seu editor preferido.
Primeiro, temos que criar nosso projeto e instalar as bibliotecas. Nosso projeto terá o nome de aranha_lelivros. Após ser devidamente criado, é a hora de instalar as bibliotecas e, para quem nunca realizou esse processo, deixo os links das documentações.
Com nosso ambiente configurado vamos partir para o desenvolvimento.
Dentro do projeto, crie um arquivo chamado aranha.py e importe as bibliotecas.
#1 Primeiro vamos identificar onde estão as informações que queremos dentro do HTML da página, para isso vamos usar a ferramenta de inspecionar do seu navegador, no meu caso será o Google Chrome. Ao inspecionar a página, notamos que os livros ficam dentro de um elemento HTML que possuiu uma tag ul com o atributo class=”prot
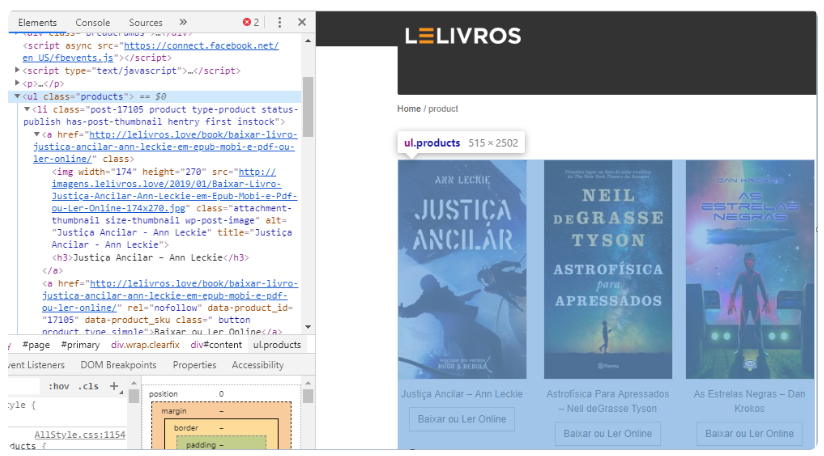
Agora que encontramos a box de livros, temos que encontrar onde está o título e o link que leva a página específica do exemplar. Indo mais a fundo no HTML vimos que dentro da tag ul temos outro elemento o: <li class=”post-17105 product type-product status-publish has-post-thumbnail hentry first instock”>, que por sua vez contém dentro dele outro elemento o: <a>, que contém nele o atributo href que armazena o link da página do livro, que é exatamente o que queremos. Dentro da tag: <a>, tem mais duas tags, <img> e <h3>, que contém nosso outro valor procurado, o título do livro.
#2 Com o caminho dos dados mapeados, vamos para o nosso arquivo aranha.py. Escreveremos os seguintes códigos:
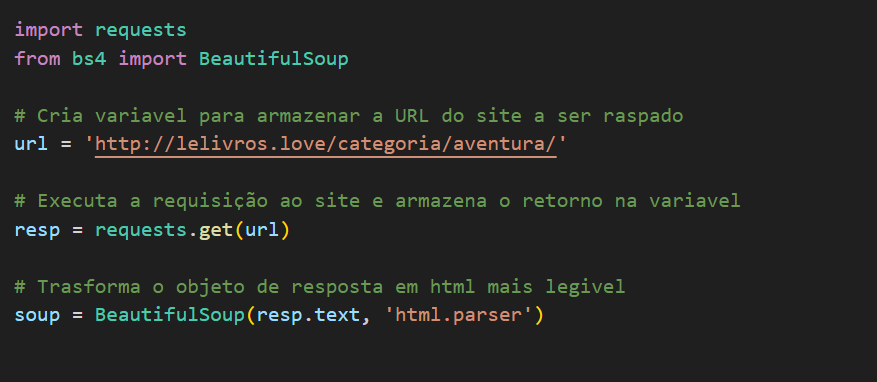
Conseguimos obter o HTML da página e converter para um objeto BeautifulSoup.
#3 Nesse terceiro passo, vamos navegar entre os elementos HTML e encontrar nossos dados e extraí-los. O código fica assim:
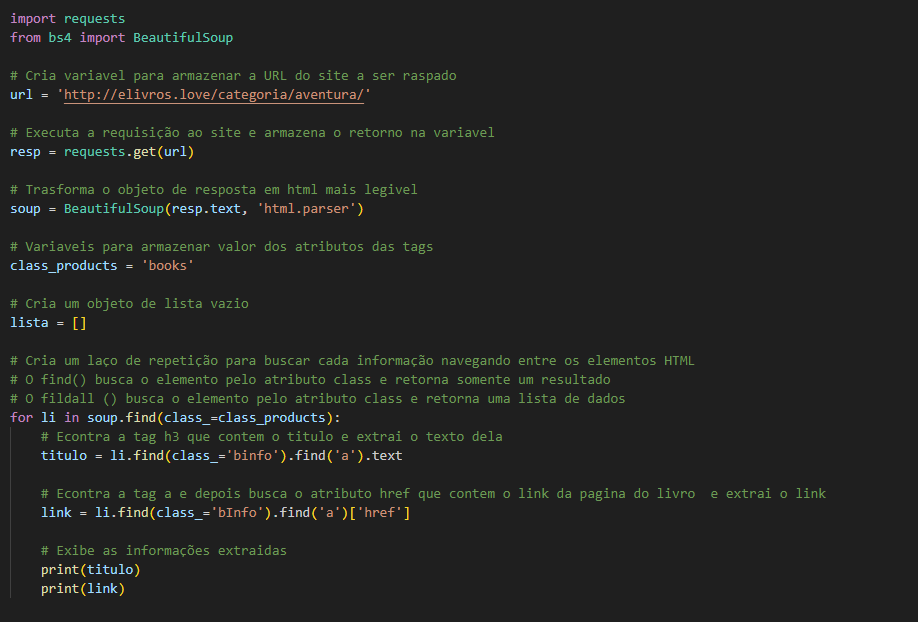
Ao ser executado gera a seguinte saída.
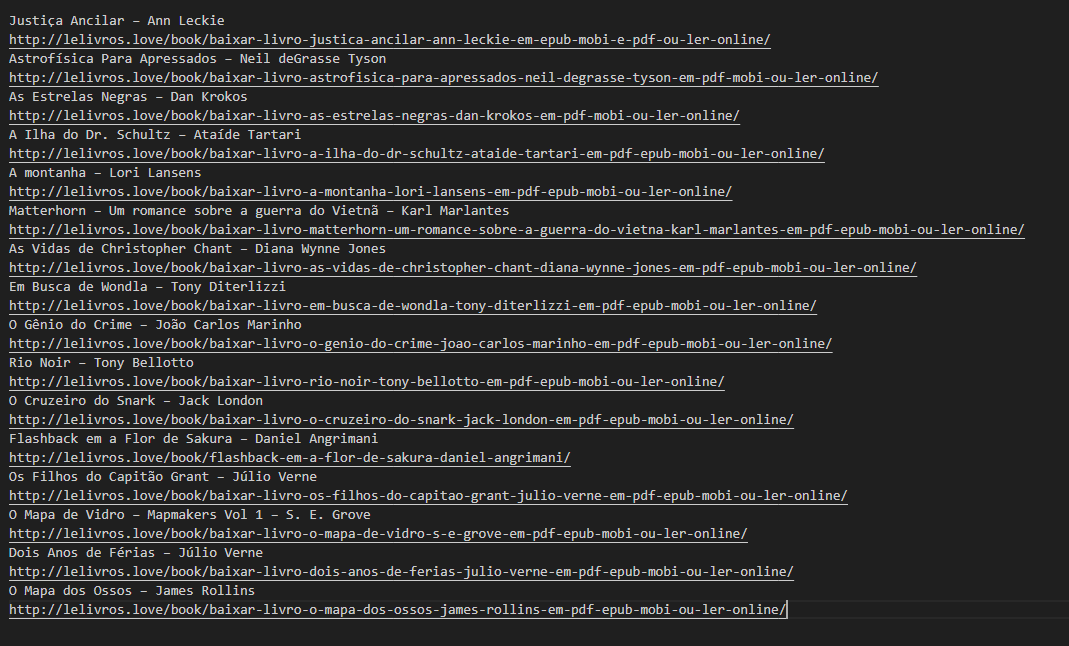
#4 Para melhor estruturação dos dados, criaremos um objeto dicionário e, em seguida, salvaremos em um arquivo chamado dados_livros.json.
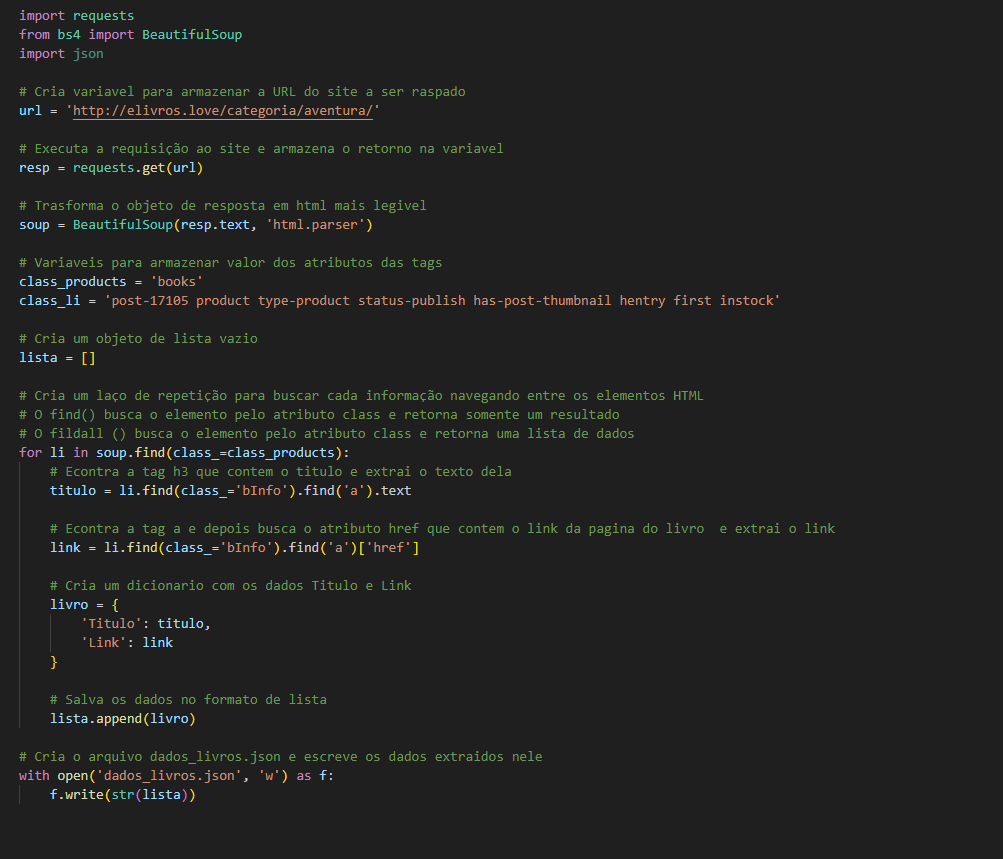
Terá a seguinte saída.

Conclusão
Com apenas alguns passos fomos capazes de extrair e armazenar dados de um website que não possui uma API para consumo de dados. Esse foi apenas um exemplo simples do que se pode fazer com a técnica de Web Scraping, que é versátil e poderosa. Enfim, agora você sabe o que é e como implementar um “robô raspador de dados”. No exemplo extraímos dados apenas da primeira página, deixo como desafio a você fazer a extração das demais páginas.
*“As opiniões aqui colocadas refletem a minha opinião pessoal e não necessariamente a opinião da Compass UOL.”




