Introdução
Nos últimos anos empresas vem coletando uma grande quantidade de dados de múltiplas fontes distintas (ERP, CRM, E-Commerce, IoT…), analisar de forma centralizada este grande volume de dados e disponibilizar para equipes de Negócios, Analistas e Cientistas de Dados é, no mínimo, desafiador.
Historicamente, muitas soluções diferentes foram criadas e utilizadas para atender a essa necessidade: um Banco de Dados, um Data Warehouse e, durante a última década, o conceito de Data Lake. Todas essas soluções tiveram seus benefícios óbvios na época, mas também diferentes tipos de limitações que se tornaram aparentes conforme as necessidades de gerenciamento de dados mudaram ao longo dos anos. O surgimento da nuvem está criando uma oportunidade para as equipes de dados repensarem suas abordagens. Dados nas plataformas de cloud (nuvem) moderna estão seguindo uma nova arquitetura – Lakehouse.
O Lakehouse simplifica radicalmente a infraestrutura de dados e acelera a inovação em uma era em que a Análise de Dados e o Machine Learning (Aprendizagem de Máquina) vem tomando conta das empresas. Essa nova arquitetura mescla as melhores funcionalidade dos Data Lakes com as melhores dos Data Warehouse. Portanto, os mais tradicionais cases de Data Warehouse são suportados na abordagem Lakehouse.
Banco de Dados, Data Warehouse e Data Lakes (Necessidades e Limitações)
O gerenciamento de dados vem mudando com o passar dos anos conforme a necessidade de acesso mais rápido aos dados vem crescendo, dados estes estruturados e não estruturados, com grande volumetria e múltiplas origens.
Primeiramente vieram os bancos de dados relacionais, que as empresas utilizavam para coletar, armazenar e analisar dados de forma simples e confiável. Por muitos anos eles foram suficientes pela relativamente “baixa” quantidade de dados.
Veio a internet, as empresas começaram a mergulhar em dados, e um banco de dados não era mais o suficiente, então passaram a criar vários bancos de dados organizados por linha de negócio, por exemplo. Esse volume de dados continuou a crescer, e muitas empresas se viram com diversos de bancos de dados que não se conversavam (silos de dados), onde normalmente não conseguiam transformar seus dados em insights para o negócio. Nasceu assim a necessidade das empresas em integrar estes dados.
Nos anos 80, os Data Warehouses (DW) nasceram para atender essa necessidade de armazenar informações relativas às diversas atividades (diversos bancos de dados) de uma empresa em um único banco de dados, de forma consolidada e objetivando o apoio a decisão.
Isso suportou a necessidade das empresas por um bom tempo, mas o volume de dados continuava a crescer (big data) e novas demandas apareceram como, por exemplo, a necessidade de armazenamento e consulta de dados não estruturados, dados em tempo real, além da crescente necessidade de análises utilizando Machine Learning (ML), que não são suportados por um Data Warehouse tradicional, sem contar o alto custo de manutenção e escalabilidade de um DW. Foi daí que surgiram os Data Lakes.
Para tornar possível a análise de big data em vários formatos e para abordar as preocupações sobre o custo e outras limitações dos Data Warehouses, o Apache Hadoop surgiu como um software distribuído de código aberto e tecnologia de processamento de dados. O Apache Hadoop é uma coleção de software de código aberto para análise de big data que permitiu grandes volumes de dados serem processados com clusters de computadores trabalhando em paralelo, aí nasceram os primeiros Data Lakes. Logo após a introdução do Hadoop, o Spark foi lançado. Spark foi o primeiro mecanismo de análise unificado que facilitou dimensionar grandes processamento de dados, análise SQL e ML. Spark também foi 100 vezes mais rápido do que o Hadoop.
Hoje, muitas arquiteturas de dados modernas usam o Spark como mecanismo de processamento massivo de dados, que permite aos engenheiros e cientistas de dados realizar ETL (Extract, Transform and Load) ou ELT (Extract, Load and Transform), refinar seus dados e treinar seus modelos de ML. Funcionando em nuvem, essas novas arquiteturas geram uma maior flexibilidade, praticidade e redução de custo (principalmente de armazenamento, exemplo: AWS S3 – blob storage).
Embora adequados para o armazenamento de dados, os Data Lakes carecem de alguns recursos:
- Eles não suportam transações.
- Eles não impõem a qualidade dos dados.
- Sua falta de consistência e isolamento torna-o quase impossível para mesclar inserções e leituras de dados, assim como trabalhos em Lote (batch) e streaming.
Por essas razões, muitas das promessas dos Data Lakes não se materializaram e, em diversos casos, levou à perda de muitos dos benefícios anteriores dos Data Warehouses. As necessidades continuaram crescendo principalmente com os avanços recentes em IA (Inteligência Artificial), que tem sido em melhores modelos para processar dados não estruturados (texto, imagens, vídeo, áudio), esses são precisamente os tipos de dados para os quais um Data Warehouses não são otimizados.
Uma abordagem comum é utilizar vários sistemas – um Data Lake, vários Data Warehouses e outros sistemas especializados, como streaming, séries temporais, bancos de dados de imagens e de grafos. No entanto, ter uma infinidade de sistemas introduz complexidade adicional e, mais importante, introduz atrasos, pois os profissionais de dados precisam mover ou copiar dados entre sistemas diferentes.
Lakehouse
Um Lakehouse é uma nova arquitetura que permite aos usuários fazer tudo, desde BI, análise SQL, ciência de dados e ML em uma única plataforma. O Lakehouse tem uma abordagem opinativa para construir Data Lakes, adicionando atributos de Data Warehouses – confiabilidade, desempenho e qualidade, mantendo a abertura e escala de Data Lakes. Suporta:
- Transações ACID: toda operação é transacional, isso significa que cada operação ou é totalmente bem-sucedida ou é abortada. Quando abortado, é registrado e qualquer resíduo é limpo para que você possa tentar novamente mais tarde. A modificação dos dados existentes é possível porque as transações permitem que você faça atualizações refinadas. As operações em tempo real são consistentes e versões de dados históricos são armazenadas automaticamente. O Lakehouse também fornece instantâneos (snapshots) de dados para permitir que os desenvolvedores facilmente acessem e revertam para versões anteriores para auditorias ou reproduções de experimentos.
- Manipulação de grandes metadados: Lakehouse trata da arquitetura metadados assim como dados, aproveitando a capacidade de processamento distribuído do Apache Spark utilizada para lidar com todos os seus metadados. Como resultado, ele pode lidar com tabelas em escala de petabyte com bilhões de partições e arquivos com facilidade.
- Indexação: junto com o particionamento de dados, a arquitetura do lakehouse inclui várias técnicas estatísticas, como filtros bloom (bloom filters) e data skipping para evitar a leitura de grandes porções dos dados no total e, portanto, oferecem acelerações massivas.
- Validação de esquema: todos os seus dados que vão para uma tabela devem aderir estritamente a um esquema definido. Se os dados não satisfizerem o esquema, ele é movido para uma quarentena em que você pode examiná-lo mais tarde e resolver os problemas.
No passado, a tomada de decisão era baseada principalmente em dados estruturados de sistemas operacionais. É essencial para um sistema de gerenciamento de dados de hoje ser muito mais flexível e suportar dados não estruturados em basicamente qualquer formato, permitindo técnicas avançadas de ML. Com a abordagem Lakehouse, essa flexibilidade é alcançada simplificando profundamente a infraestrutura de dados para permitir a aceleração e inovação. Isso é especialmente importante em um momento em que o Machine Learning vem revolucionando todas as áreas da indústria e exige uma infraestrutura elástica suportando velocidade e eficiência operacional.
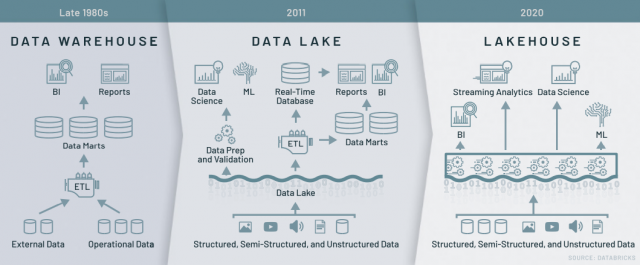
Figura 1 – Comparação de Arquiteturas de DW, Datalake e Lakehouse (fonte:https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html)
Vantagens e diferenciais:
- Suporta dados estruturados, semiestruturados e não estruturados.
- Baixo custo operacional e sem dependência de fornecedor.
- Alta escalabilidade e baixo custo.
- Suporte a BI, assim como os DW, só que também dá suporte a ML.
- Suporta controle de versão dos dados.
- Remoção de redundância de dados e aumento de segurança.
Desafios que podem ser superados com uma abordagem lakehouse:
- Unificação da equipe de dados: um dos maiores benefícios de um Lakehouse é que ele unifica todas suas equipes de dados (engenheiros de dados, cientistas de dados e analistas – em uma única arquitetura).
- Silos de dados: facilita a quebra de silos de dados, fornecendo uma cópia completa e consistente de todos seus dados em um local centralizado. Isso permite que todos em sua organização possam acessar e gerenciar tanto dados estruturados como não estruturados.
- Dados obsoletos: de forma contínua, a abordagem Lakehouse pode processar lote (batch) e streaming de dados, atualização de tabelas e painéis quase em tempo real (near real time) para que seus dados estejam sempre gerando valor, permanecendo atualizado e nunca se tornando obsoleto.
- Aprisionamento à fornecedores: usa formatos e padrões abertos que permitem que seus dados sejam armazenados independentemente das ferramentas que você usa atualmente para processar isso, tornando mais fácil a qualquer momento migrar seus dados para um outro fornecedor ou tecnologia.
Definindo valores para construção de Lakehouses confiáveis
Lakehouses permitem eficiência na ingestão de dados (batch | streaming), na construção de pipelines de dados escalonáveis e na execução destes em produção, além de automatizar todo este fluxo, garantindo confiabilidade e escala.
Com a Lakehouse, você se beneficia de uma abordagem unificada e arquitetura simplificada que traz confiabilidade em todo o seu processamento, seja em batch e/ou streaming. Você experimenta pipelines de dados robustos que garantem confiabilidade de dados com atomicidade, consistência, isolamento e durabilidade (ACID) e garantias de qualidade de dados em todo o processo.
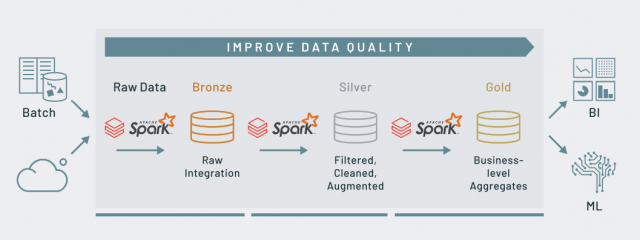
Figura 2 -Pipeline de dados (fonte: https://databricks.com/blog/2020/06/02/monitor-your-databricks-workspace-with-audit-logs.html)
A figura acima mostra um pipeline de dados simplificado e eficiente. Nesta configuração, você experimenta redução de tempo computacional e custos com uma execução em nuvem escalável. Esse processo é alimentado por clusters Spark altamente otimizados e recursos de nuvem elástica que podem ser escalonados automaticamente para cima e para baixo, dependendo da carga de trabalho (otimizando o custo).
Um exemplo didático de utilização…
Uma empresa do ramo PET, durante o ano de 2020, precisou migrar seus negócios para a internet. Criaram uma loja online completamente independente do ERP utilizados pelas lojas físicas e hoje precisam ter um controle melhor destas informações da loja online e, ainda, integrado com seu ERP.
No diagrama abaixo, uma sugestão de arquitetura de um Lakehouse para a empresa PET:
Leitura rápida da imagem abaixo: Ingestão de dados do ERP (pelo Amazon RDS – via CDC) e da Loja online (via Amazon Kinesis) | Armazenamento dos dados no Amazon S3 | AWS Lake Formation para Catalogação de dados, Segurança dos dados, Pipeline, Tratamento de Dados, garantindo ACID com Lambdas e Step Functions | Análises de dados (Amazon Athena) | Visualização de dados (Power BI) | Análises utilizando Machine Learning (Amazon Sagemaker).
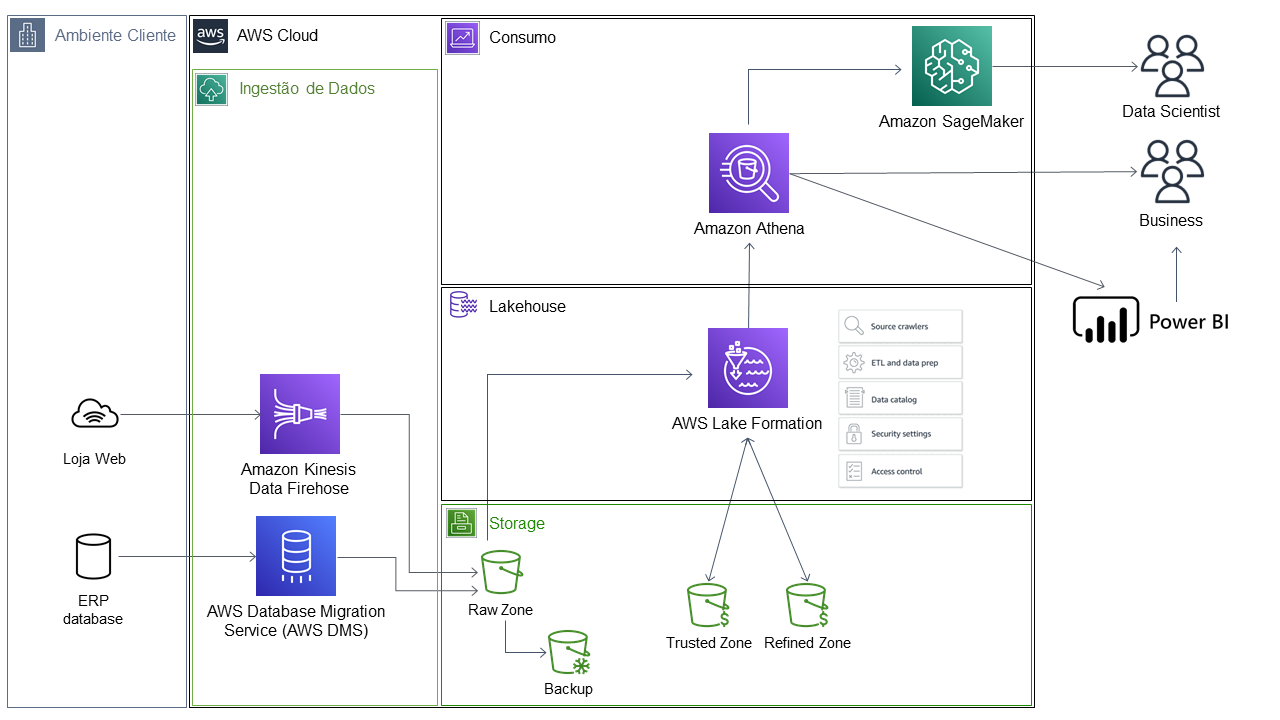
Figura 3 -Arquitetura de exemplo da Empresa Pet (fonte: própria)
Conclusão
Neste mundo cada dia mais conectado e rodeado de dados, dos mais diversos tipos e formatos, cresce a necessidade de centralizarmos estas informações para que possamos chegar a análises, resultados e descobertas (insights) confiáveis e de qualidade.




