Neste artigo buscamos mostrar alguns dos desafios enfrentados na criação de um Data Lake na Cloud da AWS, mais especificamente utilizando o serviço AWS Database Migration Service (AWS DMS) para capturar dados de um banco de dados (SQL Server) de produção (ambiente fora da cloud AWS) e levar estes dados para o Amazon S3 (AWS). O desafio consiste em extrair os dados de um banco relacional em “near real time”, em que o cliente necessita que os dados estejam o mais atualizado possível para atender às análises e demandas crescentes de seu negócio.
O AWS DMS é um serviço para migrar bancos de dados para a nuvem Amazon Web Services (AWS). De forma rápida e segura, você consegue criar uma instância de replicação com conexão ao banco de origem e conexão ao destino na AWS. Então, o que você precisa é configurar tarefas informando quais tabelas você deseja extrair do banco de dados. Com o DMS é possível configurar tarefas utilizando a técnica de “Change Data Capture” (CDC) para capturar as alterações em andamento do banco de dados de origem. Para este tipo de tarefa funcionar devem ser habilitadas algumas configurações na origem, como os logs do banco, pois essa solução de CDC é baseada em ler os logs de transação e replicar para o destino. Essa técnica é desenvolvida dessa forma para deixar o consumo do DMS separado do transacional, diminuindo as chances de qualquer impacto no sistema.
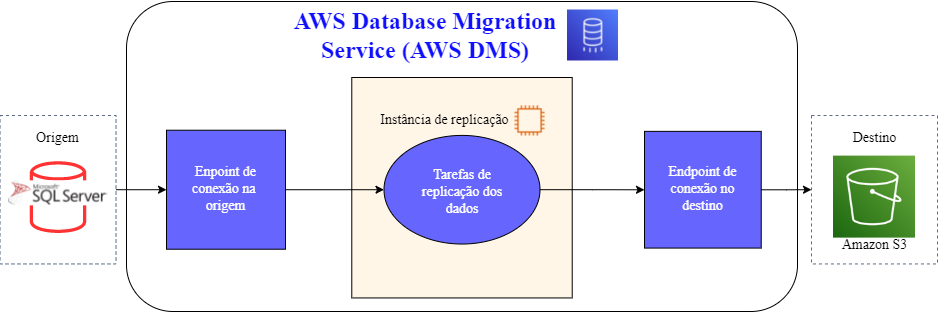
Figura 1. Arquitetura DMS | Fonte: Elaborado pelo autor
Na fase de desenvolvimento do projeto não tínhamos conhecimento do comportamento das tabelas, então escolhemos criar uma instância de replicação do DMS da classe C5 (otimizada para computação – CPU). Optamos por essa instância por ter um bom custo/benefício, comparado às outras instâncias. Criamos tarefas do tipo carga máxima mais replicação contínua (CDC) do DMS, para consumir as tabelas. Então, começamos a monitorar a instância de replicação e as tarefas do DMS usando as métricas do Amazon CloudWatch para entendermos como seria o comportamento das cargas e replicação dos dados.
O primeiro problema que tivemos foi nas cargas máximas das tabelas, pois havia uma alta latência de rede devido a distância da região que estava a nossa instância de replicação e a região do banco de dados de origem (do cliente). A solução para este primeiro problema foi colocarmos a nossa instância de replicação na mesma região do banco de dados de origem, e com essa proximidade (mesmo em cloud distintas), tivemos um ganho de velocidade muito alto nas cargas das tabelas. Além disso, observamos que o IP da instância pode mudar a cada manutenção semanal obrigatória que ocorre nela e necessitamos de um IP fixo na instância para o cliente conseguir liberar o acesso da nossa máquina no servidor do banco de dados deles. Para resolver este caso, colocamos a nossa instância em uma VPC com saída para a internet utilizando o Elastic IP que é estático.
O segundo problema foi o que levamos mais tempo para entender e solucionar, pois se tratava de estabilizar a replicação contínua (CDC) das tabelas que em alguns casos, devido ao alto número de transações, atrasava muito e não atendia ao pedido de “near real time” solicitado pelo cliente. Em contato com a equipe de banco de dados do cliente, o DBA identificou muitas sessões do usuário do DMS com conexão em aberto e um consumo muito alto de CPU por parte do servidor do banco de dados de origem e as sessões não encerravam, não conseguindo enviar dados, pois não havia vazão. O cliente então nos comunicou que haviam algumas rotinas (do sistema ERP) sendo executadas naquele momento que atualizam um número muito alto de registros, e com isso gerando concorrência. Verificando as métricas de algumas tarefas do DMS observamos uma crescente na métrica de “CDCLatencySource” que significa que o processo de captura da origem está atrasado, pois essa métrica mostra o intervalo, em segundos, entre o último evento capturado do endpoint de origem e o timestamp atual do sistema. Analisando as métricas da instância de replicação, identificamos que a métrica “WriteIOPS”, que mostra o número de operações de E/S de gravação de disco por segundo, estava fixa no número de 300 operações de E/S por segundo (IOPS). A nossa instância possuía 100 GB de disco naquele momento, e identificamos que para aumentar a quantidade de IOPS precisávamos aumentar o tamanho do disco, pois são 3 IOPS por GB de tamanho do disco. A solução para o segundo problema foi aumentarmos a quantidade de armazenamento e a replicação dos dados voltou a funcionar (aumentamos de 300 para 3000 IOPS). Na figura 2, conseguimos visualizar o resultado de aumentar a quantidade de IOPS, pois pelo menos uma vez por dia executa uma rotina que gera muitas transações, fazendo a instância utilizar os 3000 IOPS para garantir que o banco de dados não esteja passando por nenhum gargalo de desempenho.
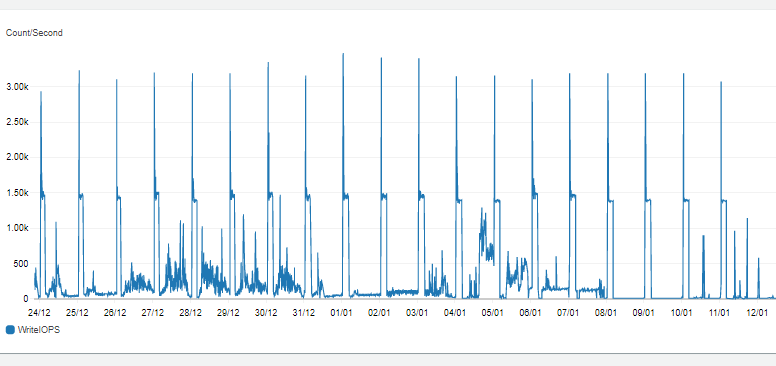
Figura 2. Métrica “WriteIOPS”, após aumentar o tamanho do disco | Fonte: Elaborado pelo autor
O terceiro problema: com o passar do tempo, o volume de dados aumentou, e a replicação dos dados voltou a ter atrasos e travamentos. Fazendo uma nova análise na nossa instância de replicação identificamos a métrica de “SwapUsage”, que mostra a quantidade de vezes que o swap é utilizado – o swap é um espaço em disco usado quando a quantidade de memória está cheia. Consultando a documentação do AWS DMS identificamos que para não ter perda de desempenho, é sempre aconselhável garantir que o DMS esteja realizando o processamento dos dados diretamente na memória. Outro ponto observado foi que para minimizar o uso de disco também é possível alterar os parâmetros de configurações das tarefas do DMS, como o “MemoryLimitTotal”, que especifica o máximo de memória que a tarefa pode usar, e o “MemoryKeepTime”, que especifica o máximo de tempo que cada transação pode ficar na memória. A solução para o terceiro problema: após toda essa análise, realizamos uma mudança na nossa instância de replicação, aumentando os recursos principalmente de memória – no caso, alteramos para uma instância da classe R5 (otimizada a memória), seguindo a documentação da AWS, que aconselha a utilização de instâncias R5 para manter um número alto de transações na memória e evitar problemas durante as replicações de dados. Na figura 3, conseguimos visualizar o momento da troca para uma instância com mais memória, dia 05/10, resultando na métrica “SwapUsage” zerada.
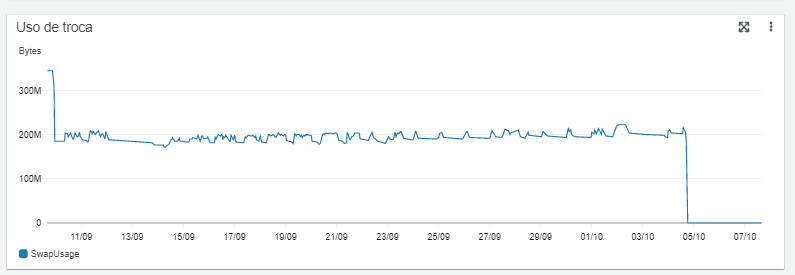
Figura 3. Métrica “SwapUsage” quando ocorreu a troca de instância do DMS | Fonte: Elaborado pelo autor
Pontos que podem ser analisados quando surgirem problemas com replicação de dados utilizando AWS DMS CDC:
- Verificação de latência entre servidor de origem e instância de replicação.
- Recursos limitados no servidor de origem.
- Recursos limitados na instância de replicação.
- Configurações de tarefas com recursos limitados.
Podemos observar que o processo de replicação de dados, utilizando de configurações “near real time”, tem diversos pontos a se observar. Aqui mostramos alguns problemas enfrentados (latência, recursos limitados, aumento no volume de dados, comportamento de tabelas…) e suas respectivas soluções. Esses pontos já podem ficar no radar, caso seja necessário implementar uma solução parecida. Espero que tenhamos ajudado de alguma forma!
Autores:
Antonio Alex de Souza – Analista de dados na Compass
Cauê Dal-Berto Rathke – Engenheiro de dados na Compass




