Shift left é a ação tomada por um time DevOps para antecipar uma ou mais etapas de validação no processo de delivery. Não é uma questão tão trivial quanto parece, visto que essa antecipação ocorre sob duas condições-chave:
Feedback: Utilizar o feedback da etapa de validação como métrica para aprovação da continuidade do delivery, preferencialmente de forma automática.
Impacto: Antecipar a etapa de validação em relação ao deploy, evitando impacto nos usuários.
Talvez essa abordagem não seja algo novo, em especial se já leu o artigo “DevOps: exorcizando o medo de mudanças”.
Mas para tornar mais claro o seu conceito, preparamos o vídeo abaixo com o objetivo de ilustrar a dinâmica shift left. Vale ressaltar o ponto em que os usuários são afetados e o feedback no processo.
Vídeo de representação da técnica de shift left no processo de delivery.
Por que adotar shift left?
O que motiva a adoção de shift left certamente é a redução de custo operacional que proporciona, decorrente de falhas no delivery. O relatório da consultoria global IDC “DevOps and the Cost of Downtime: Fortune 1000 Best Practice Metrics Quantified” ilustra o impacto de falhas em diferentes etapas do processo.
Tomaremos como exemplo uma situação em que é possível analisar um conjunto de ambientes on-premise com características clássicas de delivery tradicional (longas preparações para restauração do ambiente, janelas de execução fora do horário de risco e adoção frequente de mudanças emergenciais).
Se analisarmos as distribuições de mudanças e incidentes, não ficam claras as relações. Talvez uma tendência de mudanças acumuladas às quintas-feiras. Mas, se observamos mudanças e eventos de maior criticidade (com maior impacto financeiro), verificamos que as mudanças se acumulam próximas dos finais de semana (fora do horário comercial), e ainda que os incidentes críticos se acumulam com a proximidade do horário comercial da próxima semana.
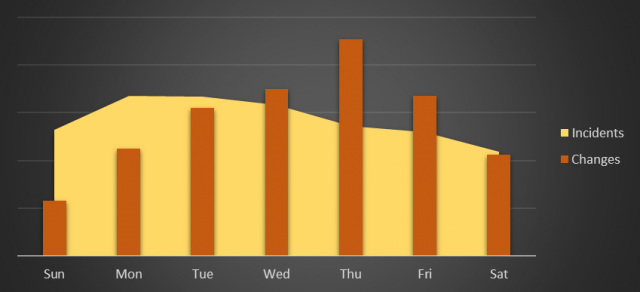
Perfil de distribuição de mudanças e incidentes executados no último semestre em ambientes on-premise (duração média das mudanças: 2,5 dias).
Algumas informações foram propositalmente omitidas.
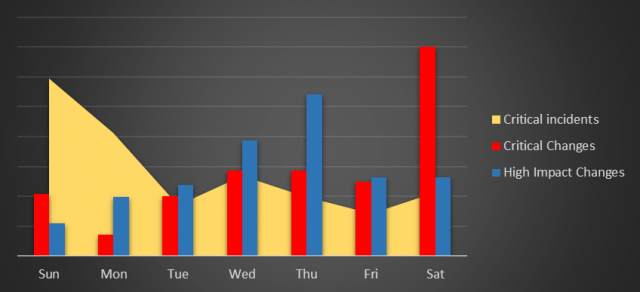
Aprofundamento da análise acima, perfil de distribuição de mudanças mais significativas e incidentes críticos.
Assim, a busca pela redução está nas etapas preliminares ao deploy e não na reação ao incidente para tentar contornar o impacto. A ideia é que ao antecipar etapas, ou seja, ao investir recursos no início do processo, minimiza-se erros para as etapas posteriores (cadeia de erros), e, claro, evitando que estes atinjam os usuários.
Outro fator significativo para a dinâmica de TI é que o shift left também promove a melhoria do “time-to-market”. A antecipação das etapas de validação reduz drasticamente o retrabalho, fazendo com que o objetivo da mudança seja alcançado facilmente (situação oposta aos incidentes críticos pós janelas de mudanças). As mudanças são avaliadas frequentemente e a abrangência desses testes pode ser constantemente incrementada.
Veja as ilustrações abaixo sobre alocação de recursos.
Dinâmica de antecipação da alocação de recursos no shift left.
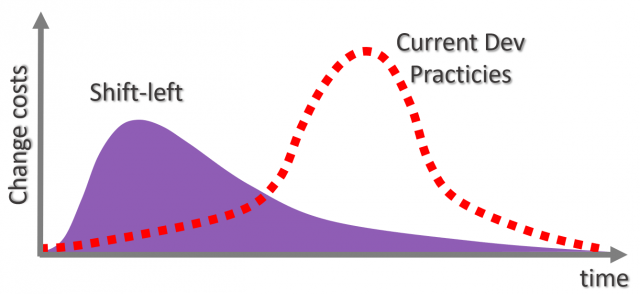
Alocação de custos em mudanças na abordagem tradicional e na abordagem shift left.
A técnica de shift left é poderosa, mas um ponto importante é que ela seja usada de forma positiva para evolução do processo de delivery. Deve-se evitar restrições severas, respeitando a maturidade e buscando a melhoria constante do processo. A pior cilada é utilizar o shift left como “ferramenta de burocratização” para evitar entregas.
Shift left na prática
A seguir destacamos um vídeo que mostra uma abordagem cloud agnostic para o shift left. Trata-se de uma apresentação no evento Dynatrace Perform 2018, em que mostramos um pipeline que recebe feedback da monitoração sintética de experiência do usuário, simulando o uso do blog do e-commerce. Ilustramos o comportamento do delivery em uma situação forçada de erro no blog, em que o delivery é interrompido em razão das premissas de validação.
Se considerarmos soluções cloud native, é possível pensar de maneira mais simples em obter eventos dos recursos de cloud e interpretar seus status pelos pipelines durante o processo de delivery. Explore esses materiais:
Se existe shift left, existe shift right?
Sim, existe! Mas esse conceito está associado a metadados que classificam os objetos do processo de delivery. Ou seja, shift right pode ser tags que marcam como “produção”, componentes que foram entregues e validados, permitindo que sistemas de apoio operacional possam identificar facilmente novas versões, para ativar tratamentos de eventos ou comparar performance com versões anteriores.
Na prática
O conceito de tag é semelhante em muitos sistemas de TI, mas cada cloud tem seu conjunto de sugestões. O importante é notar que o conceito de shift right está presente em todas.
Artigo elaborado por Marcus Camillo e Jonatas Silva Lopes.



