Deployment talvez seja o tema da cultura DevOps que mais gera expectativas nas pessoas e empresas. A capacidade de fazer entregas frequentes para o negócio, sem impacto nos serviços, é algo que parece utópico para muitas arquiteturas. Por isso, neste post serão tratadas algumas das formas mais populares de deployment, analisando suas vantagens quanto ao uso de recursos, impacto nos usuários e eventuais restrições de arquitetura.
O impacto nos usuários/sistemas, o famoso “downtime”, tem muitas perspectivas de mitigações nos diferentes frameworks de gestão de TI. Para ajudar na interpretação, vamos considerar o downtime como o tempo que o serviço fica fora, independentemente se o negócio permite janelas de manutenções ou alinhamento com os usuários.
Leia também: Devops: execucão de mudancas estrategicas sem medo

“Big bang” deploy
Este nome não é um consenso entre os times de TI, mas a prática é popular, especialmente em ambientes on-premise. O conceito por trás é o do deployment executado como se fosse uma “recriação”, ou seja, com grande esforço para instalação, downtime perceptível pelos usuários e trabalhosos processos de rollback.
Basicamente nesse processo, a versão atual do serviço ativo é substituída por uma nova versão no mesmo ambiente, o que faz com que os serviços fiquem inoperantes durante a instalação. Para as adversidades do delivery, existe o processo de rollback, que envolve complexas atividades de backup e o restore que inevitavelmente interromperá mais uma vez os serviços.
Essa sequência de atividades envolve muitas equipes, principalmente para as etapas de preparação e validação, sem falar nas extensas documentações que servem quase que exclusivamente de evidências do processo. A principal característica desse tipo de abordagem de deployment é que todo esse esforço é perdido após a execução da mudança (o feedback é ineficiente para transformar o processo), pelo menos no médio prazo, pois tudo fica restrito aos documentos e às experiências das pessoas. E esses documentos são inflexíveis.
O gif abaixo ilustra a percepção desse tipo de deployment. Veja que o principal desafio está em atualizar um único ambiente. Agora, considere a possibilidade da mudança de arquitetura.
Blue/Green deployment
Em princípio, a descrição da abordagem “big bang” deployment sugere que grande parte do problema está no deployment no mesmo ambiente. De certa forma, isso é verdade. Mas o problema está na obrigatoriedade de ter um único ambiente operacional, seja por questões orçamentárias, tecnológicas e/ou regulatórias.
O blue/green deployment aborda esse tema com o uso de, ao menos, um ambiente equivalente ao que está em operação, tanto em capacidade quanto em funcionalidade. De forma que a nova versão possa ser implementada nesse ambiente apartado sem afetar os usuários/sistemas ativos.
A característica mais marcante do blue/green deployment está no momento do redirecionamento dos usuários, em que todos os usuários são submetidos à nova versão de uma vez (isso mesmo, uma lógica 0 ou 1). A virada normalmente é acompanhada pela monitoração de métricas operacionais e de negócio (transações por segundo, usuários conectados, utilização de memória/CPU, tempo de resposta etc).
Assim, em caso de desvios de comportamento, possa ser adotado o rollback por meio do redirecionamento dos usuários para a versão anterior – infinitamente mais rápido do que restaurar um backup, reinstalar binários, entre outros procedimentos.
Um ponto que merece maior esclarecimento é o do redirecionamento dos usuários. Esta ação parece simples nas linhas do blog, mas isso depende das características do serviço. Contudo, esse redirecionamento pode ocorrer com a substituição de containers dentro de um host/cluster, alteração de CNAME no DNS, alteração dos hosts sob o load balancer/proxy-reverso, ou até mesmo alteração no roteamento IP. No final deste artigo, você encontrará referências com detalhes das práticas em cloud providers.
Considerando o paralelismo dos ambientes no blue/green deployment, é possível destacar o custo como a principal restrição para o seu uso, especialmente em ambientes on-premise (licenças, hardware, serviços etc). Mas o ambiente com a nova versão pode ser temporário, ou seja, construído a partir de automações (infra as code, gerenciadores de configuração e versionadores). No gif abaixo, mostramos uma situação em que o novo ambiente é criado no processo de deployment.
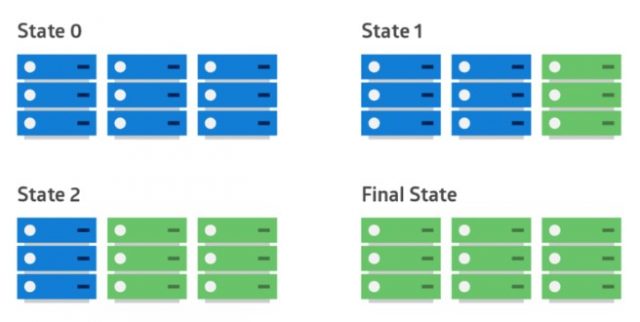
Rolling deployment
O processo de rolling deployment, assim como o blue/green deployment, é baseado na utilização de ambientes para que versões diferentes coexistam e o processo de restore seja mais rápido, minimizando o downtime para os usuários/sistemas.
Contudo, em vez de criar/dedicar um ambiente, o rolling deployment se propõe a utilizar os recursos do ambiente de alta disponibilidade, ou seja, em arquiteturas N+1 ou N+M pode-se utilizar parte do ambiente ativo para receber a nova versão. Quando existirem problemas, os componentes com a nova versão são desativados (isolados), e a resiliência do ambiente atenderá a carga com a versão anterior.
Em caso de sucesso (sem detecção de impacto), gradativamente, a nova versão é instalada no resto do ambiente. Resumindo, nessa técnica, sacrifica-se temporariamente a resiliência em nome da experimentação no deployment.
Normalmente, nessa técnica, a distribuição de usuários ocorre de forma equilibrada pelo número de ambientes, pois eles podem estar sob um loadbalancer (ou algo equivalente).
https://dev.to/mostlyjason/intro-to-deployment-strategies-blue-green-canary-and-more-3a3
Canary deployment
O canary deployment é a técnica que se preocupa tanto com o paralelismo de ambientes (custos), quanto com o impacto nos usuários pela nova versão no deployment (incluindo rollback). O mais interessante é que isso está presente no nome da técnica, pois “canary deployment” remete à ideia do uso de pássaros em gaiolas para detecção de vazamento de gás nas minas de carvão.
No caso da TI, a questão é separar um número relativamente pequeno de usuários/sistemas para experimentar a nova versão, de forma que o ambiente paralelo cresça conforme aumenta a demanda controlada e quando desvios não sejam observados no comportamento da nova versão.
O processo de rollback é semelhante ao caso do blue/green deployment, em que os usuários da nova versão são direcionados para versão anterior, mas com impacto ainda mais restrito.
Para que essa técnica seja colocada em prática, as formas são semelhantes ao blue/green deployment, contudo, a regra de mudança deve ser condicionada a um contexto que controle o número de usuários submetidos à nova versão. É preciso evitar que aleatoriamente usuários sejam submetidos às duas versões.
No caso dos gifs abaixo, foi usado um proxy-reverso que persistiria sessões para cada versão, mas que distribuiria novas sessões de acordo com um fator numérico. Observe no gif a transição de sessões de uma versão para outra, as etapas podem ser tão longas e quantas forem necessárias, isso dependerá das características do negócio e dos serviços.
Teste A/B
Diferentemente do que se pensa, teste A/B não é uma técnica para deployment, mas uma técnica de comparação entre funcionalidades. A diferença está na complexidade da mudança e na objetividade da avaliação (focada em um conjunto pequeno de métricas). O teste A/B normalmente trata de pequenas mudanças embarcadas no software, que são controladas por caminhos lógicos dentro do software (feature toggles).
Por exemplo, é possível comparar a mudança do comportamento dos usuários de um e-commerce da perspectiva da conversão de compra quando o menu de busca de produtos é alterado. Se esta alteração na nova versão atingir o ganho predeterminado sobre a versão anterior, a versão nova fica ativa, ou pode ser descartada. Na imagem abaixo, é apresentada a mudança da cor de um botão analisada sob a perspectiva de taxas de cliques.

https://en.wikipedia.org/wiki/A/B_testing#/media/File:A-B_testing_example.png
Conclusão
As técnicas foram organizadas de forma que elas respondessem a lista abaixo.
- Único ambiente para deployment: blue/green, rolling e canary resolvem;
- Custos do paralelismo de ambientes: rolling e canary resolvem;
- Falta de controle do impacto: canary resolve;
Contudo, a escolha da estratégia de deployment está na combinação do máximo downtime, recursos disponíveis e nível automação desejados. Mas existem situações que podem limitar o uso de algumas estratégias em razão das características dos serviços. As aplicações baseadas nas práticas de microsserviços e cloud-native tendem a ser receptivas a essas estratégias, apesar de existirem alguns componentes que precisam de atenção especial, como no caso de bancos de dados.
Independentemente da técnica adotada, existem boas práticas no processo de deployment que podem ajudar a ter uma vida mais tranquila:
- Minimize o impacto (teste com usuários internos, depois com regiões insignificantes para o produto, para então migrar os demais usuários);
- Teste novas features (como os casos do teste A/B);
- Pense em Continous Integrations e Continous Deployment (automatize testes e entregas);
- Pense em gestores de configuração e “versionadores”;
- Pense em canais de comunicação para notificação das mudanças;
- Pense em monitoração de métricas técnicas e do negócio para validação e
- Valorize e enriqueça logs.
Na prática
Existem diversas formas de implementar as estratégias de deployment, especialmente pelo fato de existirem muitos componentes que podem desempenhar o papel base para coordenar essas ações. Contudo, há duas características importantes nessas condições. A primeira é a autonomia de gerenciar os componentes por meio de APIs e a segunda, quando possível, é consumir esses componentes como serviços, minimizando o esforço operacional.
Considerando, como exemplo, o caso do blue/green deployment utilizando o redirecionamento no DNS, em uma estrutura puramente on-premise, é preciso ter uma infraestrutura de DNS, que eventualmente pode ter API para configuração dos apontamentos.
No caso de um cloud provider, como a AWS, é possível usar o serviço de DNS Route53 delegando um subdomínio e o gerenciando em cada conta. Ou seja, comparando os dois casos não haveria infraestrutura para administrar, além do ganho de maior autonomia para a equipe no caso de um serviço em um cloud provider.
Outro exemplo são as situações do rolling deployment ou canary deployment utilizando um loadbalancer. Em ambientes on-premise, normalmente, trata-se de um componente extremamente sensível em razão do seu compartilhamento entre diversos projetos. Já no caso de serviços de cloud, esse componente pode ser administrado de forma isolada de outros projetos e consumido como serviço, como no caso do AWS ELB.
Cloud-native approach
A seguir, alguns materiais de referência sobre as práticas abordadas neste artigo para inspirar uma implementação.
Blue/Green Deployment on AWS (no apêndice A, há avaliação do risco de cada técnica)
Rolling deployment on AWS Elastic Beanstalk
Canary deployment of AWS Lambda
Blue/Green deployment with Azure Traffic Manager
Canary deployment on Azure VMSS
Deployment analysis with Spinnaker on GCP
Artigo elaborado por Marcus Camillo, sólida experiência em design e operação de TI.




