Como todos nós já sabemos, dados são a base para projetos envolvendo dados, como por exemplo: análise de dados, treinamento de modelo de aprendizado de máquina (machine learning) ou para um simples painel. Assim, adquirir os dados que satisfaçam sua necessidade é extremamente importante.
No entanto, não necessariamente essas informações existem ou estão disponíveis publicamente. Além disso, há momentos em que você deseja testar seu projeto com “dados” que atendam aos seus critérios. É por isso que gerar seus dados se torna importante quando você tem certos requisitos (um deles é questão de anonimização de dados, bastante em alta devido à LGPD – Lei geral de Proteção de Dados).
Gerar dados é importante e ágil, quando coletar dados manualmente, que atendam às nossas necessidades, levam tempo para ser coletados. Por esse motivo, poderíamos tentar sintetizar essa informação com linguagem de programação. Aqui iremos apresentar alguns (3) pacotes em Python que geram dados sintéticos, e no final comentaremos também sobre dados desbalanceados. Esses dados podem ser gerados e utilizados em qualquer projeto que você desejar.
Faker
Faker é um pacote Python, muito simples e intuitivo, desenvolvido para simplificar a geração de dados sintéticos. Vamos testar?
Vamos instalar o Faker :
pip install Faker
Agora iniciar a classe…
from faker import Faker
fake = Faker()
Agora podemos gerar diversos dados sintéticos. Por exemplo, criaríamos um nome de dados sintéticos.
fake.name()
![]()
O resultado é o nome de uma pessoa quando usamos o atributo.name da classe Faker. Dados sintéticos seriam produzidos aleatoriamente toda vez que executamos o atributo. Executar novamente…
![]()
O resultado é um nome diferente da nossa iteração anterior. O processo de randomização é importante na geração de dados sintéticos porque queremos uma variabilidade em nosso conjunto de dados.
Aqui não se limita à variável de nome — o outro exemplo é endereço (address), bank, jobs, bar-code, pontuação de crédito e muito mais. No pacote Faker, esse gerador é chamado de Provider. Mais detalhes, vejam na documentação e para mais exemplos, consulte: exemplos.
SDV – Synthetic Data Vault
O segundo pacote é o SDV, ou Synthetic Data Vault, que serve para gerar dados sintéticos com base no conjunto de dados fornecido. Os dados gerados podem ser uma única tabela, várias tabelas ou séries temporais, dependendo da necessidade.
Os dados gerados apresentam as mesmas propriedades e estatísticas do conjunto de dados original.
O SDV gera dados sintéticos aplicando técnicas matemáticas e modelos de aprendizado de máquina, como o modelo de aprendizado profundo (deep learning model). Mesmo que os dados contenham vários tipos de dados e dados ausentes, o SDV os tratará, portanto, só precisamos fornecer os dados (e os metadados quando necessário).
Vamos praticar?
pip instalar sdv
Iremos utilizar o dataset do Kaggle: Horse Survival Dataset (ele contém vários dados e tipos ausentes).
import pandas as pd
data = pd.read_csv(‘horse.csv’)
data.head()

O dataset está pronto e queremos gerar dados sintéticos com base no conjunto de dados. Vamos usar um dos modelos SDV Singular Table disponíveis: GaussianCopula.
from sdv.tabular import GaussianCopula
model = GaussianCopula()
model.fit(data)
O treinamento é muito fácil, precisamos apenas iniciar a classe e informar a quantidade de dados sintéticos que queremos gerar, neste caso, 200.
sample = model.sample(200)
sample.head()

Como feito acima, com o atributo .sample, obtemos os dados sintéticos randomizados. A quantidade de dados que você deseja depende do número que você passa para o atributo.
Para gerar número exclusivos para campos chave, por exemplo: hospital_number, podemos passar o parâmetro: primary_key para o modelo,
model = GaussianCopula(primary_key=’hospital_number’)
model.fit(data)
O resultado da amostra seria uma chave primária exclusiva para cada amostra gerada a partir do modelo.
Após gerar os dados e como saber quão bons são os dados sintéticos gerados? Neste caso, poderíamos usar a função: evaluate do SDV. Essa avaliação compara o dataset real com o de amostra. Existem muitos testes disponíveis, aqui usaremos apenas o Kolmogorov-Smirnov (KS) e Chi-Squared (CS).
from sdv.evaluation import evaluate
evaluate(sample, data, metrics=[‘CSTest’, ‘KSTest’], aggregate=False)

KSTest é usado para comparar as colunas contínuas e CSTest compara as colunas discretas. Ambos os testes resultam em uma pontuação normalizada entre 0 e 1, com o objetivo de maximizar a pontuação. A partir do resultado acima, podemos ver que as colunas de amostra discretas são boas (quase semelhantes aos dados reais — 0.88). Em contraste, as colunas contínuas podem ter um desvio na distribuição — 0.68. Caso queira se aprofundar mais nos métodos de avaliação do SDV, segue link da documentação.
Gretel – Gretel Synthetics
O último pacote e não menos importante é o Gretel, ou Gretel Synthetics, é um pacote de código aberto baseado em Rede Neural Recorrente (RNN) para gerar dados estruturados e não estruturados. A abordagem do pacote trata o conjunto de dados como dados de texto e treina o modelo com base nesses dados de texto. O modelo então produziria dados sintéticos com dados de texto (precisamos transformar os dados em nosso resultado pretendido).
Gretel exigia um pouco mais de poder computacional, uma vez que é baseado no RNN, então eu recomendo usar o notebook Google Colab.
No caso do Gretel, descreveremos passo a passo neste artigo, mas no link a seguir é possível consultar um tutorial no Google Colab, oferecido pela própria Gretel.
Dados desbalanceados (Imbalanced Data)
Como foi citado no início, aqui abriremos parênteses para dados desbalanceados, muito ligado com o que comentado acima!
Esse é um problema enfrentado diariamente por profissionais da área de dados de uma forma geral, mas os profissionais de aprendizagem de máquina sofrem um pouco mais, pois a base de seus modelos são dados, e dados desbalanceados podem gerar, por exemplo, modelos enviesados, o que é um grande problema para esses profissionais.
Situações em que o desbalanceamento é quase certo são em problemas de detecção de fraude e diagnóstico médicos – é intuitivo pensar que existem mais transações lícitas que criminosas, ou que o conjunto de pessoas diagnosticadas com câncer é bem menor que o conjunto de pessoas sem a doença.
Ignorar esse fato e treinar um algoritmo em cima do conjunto de dados original, pulando uma etapa intermediária de balanceamento dos dados, pode ter impactos diretos no seu projeto de Data Science. (+)
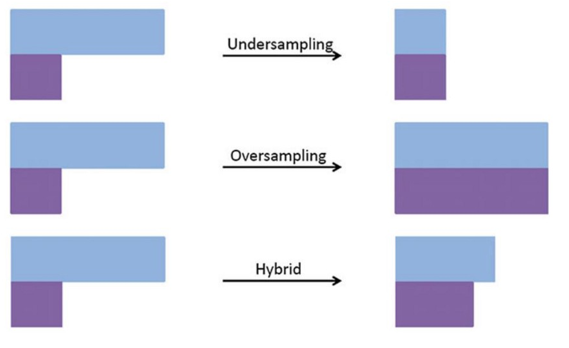
Métodos para lidar com dados desbalanceados:
Undersampling
Consiste em reduzir de forma aleatória os exemplos da classe majoritária. Abaixo algumas técnicas:
- NearMiss – É um algoritmo de undersampling que consiste em reduzir de forma aleatória os exemplos da classe majoritária, porém ele seleciona os exemplos com base na distância.
- ClusterCentroids – usa K-means para reduzir o número de amostras. Portanto, cada classe será sintetizada com os centroides do método K-means ao invés das amostras originais.
- RandomUnderSampler – é uma maneira rápida e fácil de balancear os dados selecionando aleatoriamente um subconjunto de dados para as classes de destino.
- EditedNearestNeighbours – aplica um algoritmo de vizinhos mais próximos e “edita” o conjunto de datas removendo amostras que não concordam “suficientemente” com sua vizinhança.
- RepeatedEditedNearestNeighbours – estende de EditedNearestNeighbours repetindo algoritmos várias vezes.
- AllKNN – difere de RepeatedEditedNearestNeighbours, pois o número de vizinhos do algoritmo de vizinhos mais próximos internos é aumentado a cada iteração.
Oversampling
Consiste em replicar dados aleatórios da classe minoritária. Como estamos duplicando os dados já existentes este método está propício a dar overfitting.
- SMOTE – Provavelmente o mais utilizado atualmente, consiste em gerar dados sintéticos (não duplicados) da classe minoritária a partir de vizinhos. Ele calcula quais são os vizinhos mais próximos e as características desses vizinhos para criar novos dados. Se o número de dados gerados for muito grande podemos ter um overfiting. Exemplo do uso do Smote na área da Saúde.
- RandomOverSampler – semelhante à subamostragem aleatória, esta abordagem consiste em gerar novas amostras por amostragem aleatória com substituição das amostras atualmente disponíveis (permite amostrar dados heterogêneos, por exemplo, contendo algumas strings).
- SMOTENC – é a extensão do algoritmo SMOTE em que os dados categóricos são tratados de forma diferente. O SMOTNC está funcionando apenas enquanto os dados são uma mistura de recursos categóricos e numéricos.
- SMOTEN – se o conjunto de datas consiste apenas em recursos categóricos, podemos usar a variante SMOTEN.
Híbridos
Existem duas classes prontas para usar que os implementos de aprendizado desbalanceado para combinar métodos de oversampling e undersampling são SMOTETomek e SMOTEENN.
Engenharia de features
Consiste em gerar novas features dando maior robustez ao modelo e diminuindo o viés da classe majoritária. (veja mais)
Conclusão
Devido a privacidade de dados, dificuldades em colher dados manualmente e classes desbalanceadas gerando modelos não performáticos, a demanda por dados sintéticos vem crescendo. Espero que essa breve introdução ao tema possa ajudá-los!




