Como escolher a melhor estratégia de Join
Em algum momento em nossas carreiras nos deparamos utilizando as mesmas estratégias de Joins (left, inner, other). Tendo isto em mente, aprender como Apache Spark se comporta internamente e como otimizar tais Joins pode ser de grande ajuda na hora de achar a causa de alguns erros como por exemplo falta de memória e melhorias de desempenho de Jobs Spark.
Broadcast Hash Join
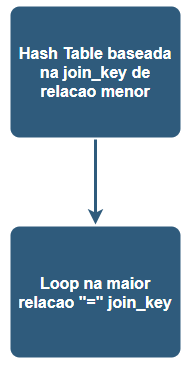
Antes de começar a explicar Broadcast Hash Join no Spark vamos primeiro entender basicamente como Hash Join funciona:
Como o nome sugere Hash Join funciona criando uma tabela Hash com base em uma Join_key de relação menor e após isso ela faz um loop sobre a relação maior para corresponder aos valores de join_key em hash. Esse tipo de Join só funciona se for usado “=” no Join. No Spark, o Hash Join desempenha uma função no nível dos executores e a estratégia é usada para juntar partições disponíveis no executor.
Como funciona o Broadcast Hash Join:
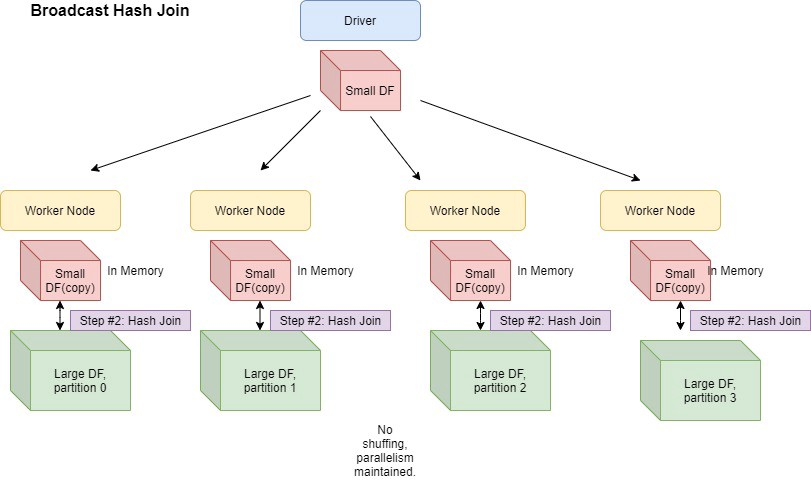
Broadcast Hash Join, funciona enviando uma cópia do menor dataframe que será utilizado no Join para todos os nodes do cluster (worker/executor) evitando assim que o Spark realize um shuffle (redistribuição de dados dentro dos workers do cluster) aumentando performance. Dessa forma você está juntando um dataframe grande com um menor.
Spark então inicia a estratégia de Join quando o tamanho de um dos lados do Join é menor que o valor limite padrão do Spark ou threshold (10M).
O threshold do Spark é configurável através da propriedade:
![]()
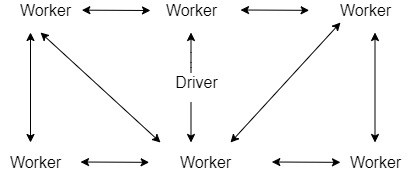
Junções de Broadcast são compartilhadas entre os executores utilizando o protocolo BitTorrent (leia mais aqui). Funciona via protocolo Peer to Peer onde cada bloco de arquivos pode ser compartilhado pelos Peer e entre eles. Dessa forma não depende-se de um único executor, todos tem os dados.
Vale destacar:
Uma junção de broadcast deve caber completamente na memória de cada executor, bem como no driver que será o ponto de partida desta transferência de dados.
Suportado somente por “=” Join.
Quanto menor o tamanho do dataframe utilizado no broadcast melhor e normalmente será velocidade assim superando as outras estratégias de Join.
O dataframe que será utilizado no broadcast irá trafegar via network (rede), mesmo utilizando intensivamente recursos de rede esta operação pode causar out of memory ou problemas de performance quando o tamanho deste for muito grande, por exemplo, quando alterado a configuração padrão de 10M do threshold.
Não será possível fazer mudanças no dataframe utilizado no broadcast, depois do broadcast. Mesmo sendo possível, ele não estará disponível no nível dos executores.
Shuffle Hash Join
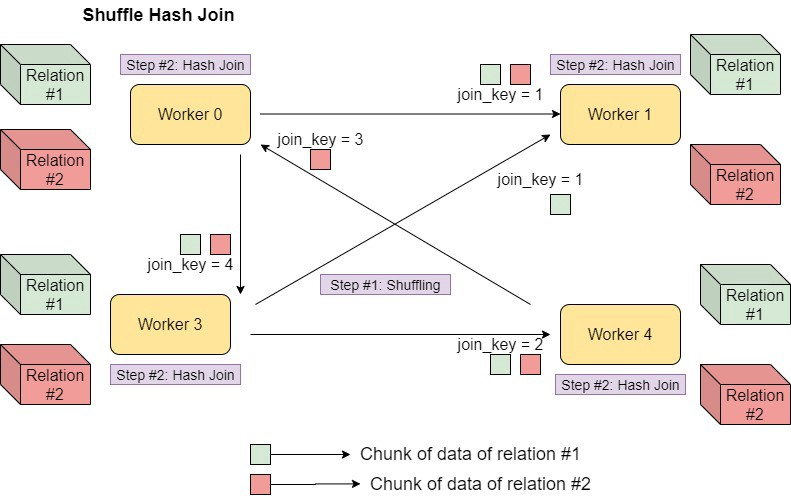
Shuffle Hash Join funciona movendo os dados que contenham o mesmo valor de Join_key para o mesmo executor (worker) e executa um Hash Join.
Cada worker junta pedaços de dados que contenham a mesma join_key e os movem para o worker quer irá processar (shuffle), após movidos os dados o último passo será combinar os dados dentro de cada worker utilizando Hash Join, sendo assim mais rápido pois os dados iguais estarão presentes no mesmo worker.
Vale destacar:
Funciona somente em “=” Joins.
A join_key não necessita ser ordenada.
Suporte todos os tipos de Joins exceto Full Outer Join.
Shuffle Sort-Merge Join
Como Sort-Merge Join funciona:
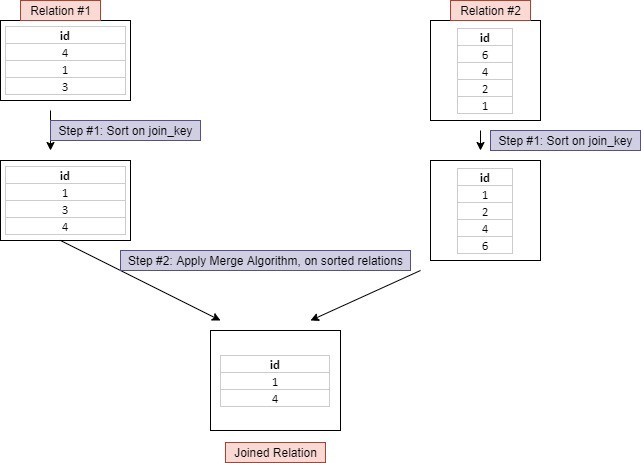
Os registros dentro de cada bloco de dados são ordenados com base na join_key e combinados (merge) formando um bloco único de dados.
Sabendo como Sort-Merge Join funciona podemos entender qual estratégia o Spark utiliza para fazer shuffle Sort-Merge Join.
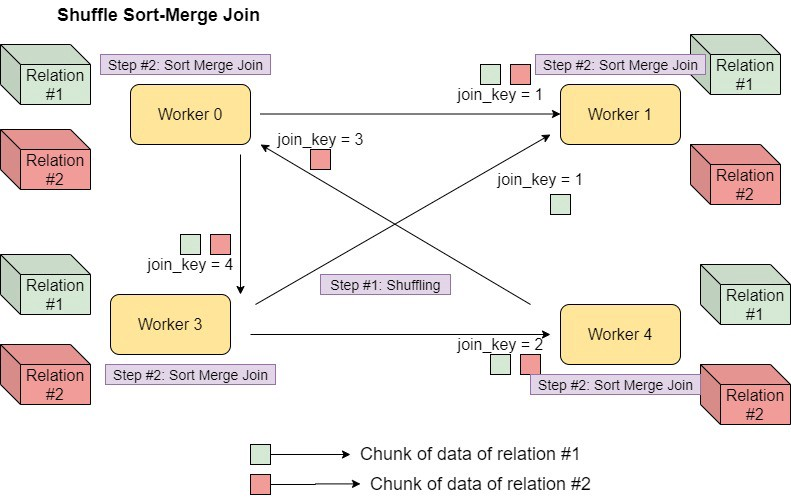
Shuffle Sort-Merge Join, utiliza um processo similar ao shuffle hash join, primeiro os dados são movidos entre os workers baseados na join_key, para que em cada worker contenha dados relacionados a mesma join_key, finalmente executa-se um sort-merge join.
Vale destacar:
Desde o Spark 2.3 esta é a estratégia de Join padrão e pode ser desativada com a propriedade:
![]()
Funciona somente em “=” Joins.
A join_key precisa obrigatoriamente ser passível de ordenação.
Suporte a todos os tipos de Join.
Broadcast nested loop join
Basicamente e um nested loop que compara os 2 blocos de dados entre eles baseados na join_key.

Esta é a estratégia mais lenta que se pode utilizar, basicamente o último recurso que será utilizado quando nenhuma das alternativas pode ser realizada.
Os dados que serão utilizados para broadcast são baseados no tipo de Join utilizado, seguindo as regras abaixo:
Right outer join – Broadcast o dataframe que está do lado esquerdo(left).
Left outer, left semi, left anti or existence join – Broadcast o dataframe que está do lado direito (right).
Inner-like join – Broadcast os 2 lados.
Para outros tipos de Join, os dados são scaneados várias vezes e isso torna o processo muito lento.
Cartesian Product Join (suffle-and-replicate nested loop join)
O produto cartesiano igual ao SQL, 2 dataframes são calculados e avaliados para que o Join seja realizado.
Como escolher uma dessas estratégias?
Dados retirados diretamente do código do Spark, veja mais aqui .
Utilize algum das dicas de Join (hints), nessa ordem:
Se for um “=” join
- Broadcast hint: broadcast hash join se o tipo de join for suportado;
- Sort merge hint: sort-merge join se as join_keys forem ordenáveis;
- Shuffle hash hint: shuffle hash join se o tipo de join for suportado;
- Shuffle replicate NL hint: cartesian_product se o join for um inner like.
Se nenhum dos hints acima forem possíveis de aplicar:
- Broadcast hash join se um dos dataframes for pequeno suficiente para ser utilizado no broadcast e se o join der suporte;
- Shuffle hash join se um dos lados for pequeno o suficiente para fazer um hash map e consideravelmente muito menor que o outro lado, e spark.sql.join.preferSortMergeJoin for false;
- Sort-merge join se as join_keys forem ordenáveis;
- Cartesian product se o join for do tipo inner;
- Broadcast nested loop join como a solução final, mas pode ser que erros de OOM(out of memory) comecem a ocorrer.
Se não for um “=” join:
- Broadcast nested loop join;
- Cartesian product se o join for do tipo inner like.
Se nenhum dos hints acima forem possíveis de aplicar:
- Broadcast nested loop join se um dos lados for pequeno o suficiente para fazer broadcast;
- Cartesian product se o join for um Inner like;
- Broadcast nested loop join solução final.




