Uma vez, durante um projeto de trabalho, surgiu uma demanda na qual era necessário realizar testes para um robô que atualiza timeframes pendentes e/ou inacabados de períodos dentro de times na nossa ferramenta de Value Stream Mapping (VSM).
- O que são Timeframes
Um timeframe é uma faixa de períodos (uma data inicial e final) que será analisada no VSM. Dentro da nossa ferramenta, cada time que possui o VSM habilitado pode adicionar esses timeframes e, a partir disso, obter métricas. Os timeframes possuem dois status: “pendente” e “atualizado”. “Pendente” significa que eles ainda não foram executados no VSM e “atualizado” significa que já foram executados alguma vez no VSM.
- O que é o Robô
O robô Data Agent, como é chamado, foi criado para eliminar a ação manual de atualizar os timeframes dos times. Sua função dentro da ferramenta é atualizar esses timeframes.
Para o novo cenário de reativação do robô, teríamos que testar cerca de 400 times para criar timeframes, mas como a equipe de qualidade poderia testar e validar a eficácia do robô se o mesmo estava calculando todos os timeframes dos 400 times? E mais importante: como adicionar 400 timeframes nesses times para fazer o teste para que não seja tão maçante para nós, profissionais de Quality Assurance (QA)?
A ideia para essa solução foi a criação de um script que adicionasse esses timeframes por meio das query/mutations do endpoint de GraphQL que temos para esse serviço.
O script é bastante simples: buscar todos os times, adicionando-os a um array e, por meio de iteração de loop, adicionar um timeframe para cada time da lista. Simples né? Mas vamos fazer um pouco mais: uma iteração linear para a execução de uma mutation leva alguns segundos ou até minutos para ser executada completamente, então, para que o script seja um pouco mais eficiente, teríamos que adicionar alguns conceitos e recursos de programação concorrente para que a execução seja mais rápida, podendo reduzir o tempo pela metade.
Mãos à obra
Começando com a estruturação do código, iremos escrever todo nosso código em um arquivo chamado “app.rb”. Usaremos uma das principais gems de GraphQL para Ruby, chamada de “graphql-client”. Essa é uma gem bastante simples que integra o Ruby a APIs em GraphQL.
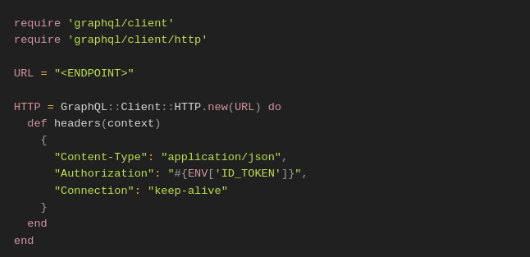
A partir do objeto HTTP, iremos criar o Schema. Nosso Schema é o “introspection” com a documentação das queries e mutations do endpoint que queremos, então é importante saber se a API possui seu introspection habilitado para podermos fazer as consultas (uma alternativa seria ter o schema.json do endpoint e adicioná-lo ao método load_schema “path/schema.json”). Também criaremos o cliente de chamadas para manipularmos as queries e mutations.

Agora que temos a estrutura básica para as futuras execuções podemos montar nossa primeira query e criar um filtro apenas para buscar as informações que queremos, finalizando a primeira etapa do script.
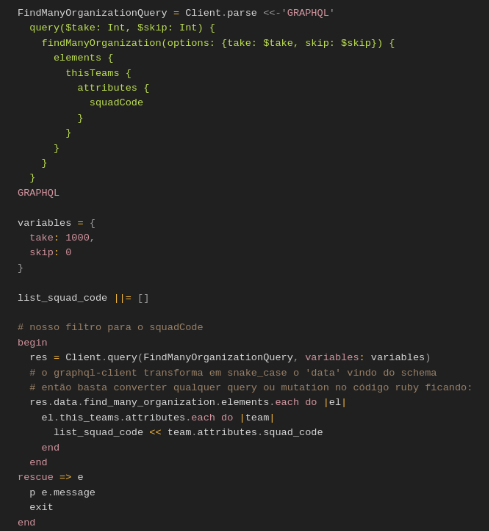
Pronto. Com o filtro completo, podemos iniciar a parte mais interessante do script. Iremos incluir duas novas bibliotecas nos requires para podermos utilizar as funcionalidades de programação concorrente e inicializaremos o objeto de fila e o semáforo. Como esse tipo de conceito pode ser um pouco mais avançado, darei um pouco mais de contexto para o funcionamento dessas duas funcionalidades (espero que as aulas de Sistemas Operacionais estejam em dia).
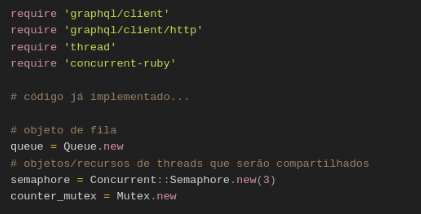
- queue: nossa variável ‘queue’ é uma estrutura de dados FIFO (first in, first out). Esse objeto vai permitir que a mutation seja executada de maneira ordenada por meio das threads.
- semaphore: Ruby não tem suporte real a semáforos, por isso utilizamos a lib ‘concurrent-ruby’. Essa entidade é usada para garantir algumas sincronizações dentro de nosso script para evitar aquelas famosas condições de corrida entre as threads. Dentro da execução do script, ‘semaphore’ irá indicar um sinal se uma thread já finalizou seu processo.
- count_mutex: o Mutex é uma classe que fornece a exclusão mútua. Ele servirá para sincronizar nosso contador que será exibido no console como uma espécie de “loading” durante a execução do script, algo como um “1/400”, “2/400”, “3/400”.
De maneira mais abrangente, a classe Mutex nos permite sincronizar variáveis e quaisquer outros objetos que serão compartilhados entre as threads, fazendo com que uma não sobrescreva a outra.
A partir de agora, iniciaremos a segunda parte do script, começando com a mutation e estruturando a fila:
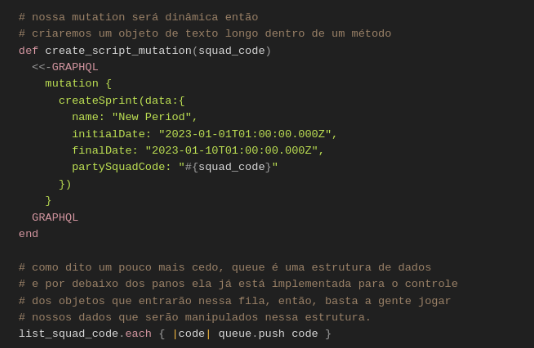
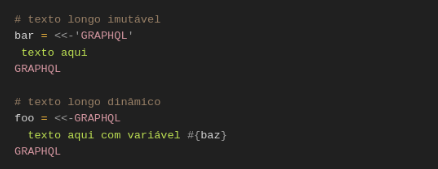
Dois centavos sobre textos longos em Ruby: podemos sempre definir se um texto será dinâmico ou constante apenas definindo aspas simples na “tag” do texto como no exemplo abaixo:
Continuando… agora iremos implementar a execução da mutation, usando tudo que já criamos.
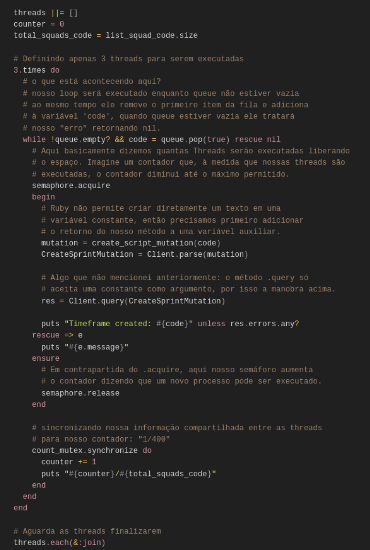
Implementar semáforos para essa quantidade de threads talvez seja “um pouco” demais, mas pensando que, se um dia tivermos outro cliente que tenha mais times e o mesmo teste seja feito para validar a eficácia de alcance de recálculo do robô, podemos aumentar a quantidade de threads e garantir que tudo vai ser executado corretamente sem condições de corrida entre as threads.
Considerações finais
Assim terminamos nosso script. Com essas técnicas a equipe de QA poderá testar de fato a eficácia do nosso robô, garantindo que ele fará todos os recálculos, visualizando, por meio dos seus logs, se todos os times foram acessados e não sobrecarregando nossa equipe, que iria criar de forma manual vários timeframes, o que seria um trabalho bem desgastante, podendo levar horas.
Considerando a questão do tempo, aqui alguns dados:
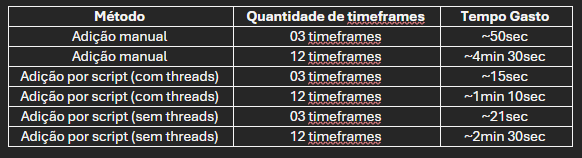
Sobre os métodos de teste e captura de tempo:
- Manual: é necessário ir até o VSM do time a partir da tela inicial da aplicação do Cockpit, clicar no botão de “adicionar”, selecionar o “radio button” de período, preencher os campos de “nome do período” e incluir uma data inicial e final por meio de um calendário e clicar no botão de salvar. Para adicionar um timeframe em outro time, é necessário voltar a tela inicial, buscar um novo time e realizar o mesmo fluxo de clicar em dois botões, preencher inputs e salvar. Sobre a cronometragem do tempo para registro, pedi o auxílio de outra pessoa para fazer o registro para quando finalizasse os três primeiros registros dos timeframes e depois os próximos até o 12º registro do timeframe.
- Script: para a validação de tempo de execução para o script com e sem threads, utilizei a biblioteca de benchmark do Ruby e implementei no código para conseguir fazer o registro de tempo de execução.
Para uma amostragem baixa, tanto o script com e sem threads, ficaram com uma margem de tempo um pouco próxima, mas que se escalasse para a quantidade total, seus valores iriam ser completamente diferentes.
A utilização de programação concorrente não só acelerou o processo de execução do script, como também trouxe flexibilidade para futuras demandas, permitindo que mais times possam ser testados de maneira eficiente e sem o risco de condições de corrida. Essa abordagem garante que a equipe de QA possa focar em outras tarefas críticas, aumentando a produtividade e assegurando a qualidade do produto final.
*As opiniões aqui colocadas refletem a minha opinião pessoal e não necessariamente a opinião da Compass UOL.




