Há um tempo, estive entusiasmado estudando sobre o paradigma funcional, fortemente utilizado em frameworks como React. Um de seus princípios, a imutabilidade, prega que nenhum dado/estado deve ser alterado, e sim evoluído e transformado. Esse princípio garante a consistência de uma informação, que pode ser acessada e lida por diversos pontos de um software, mas que nenhum destes pontos podem alterá-la, causando uma violação. Somente um único ponto isolado pode evoluir essa informação e disponibilizá-la para o restante do software consumir.
Isso despertou em mim uma imensa curiosidade sobre como construir uma informação imutável, a qual, mesmo replicada, teriam clones que não causassem impacto na informação original, pois esses clones, internamente, corresponderiam a novos endereços de memória.
Existem bibliotecas, como lodash, que possuem funções capazes de criar clones em profundidades de estruturas complexas, mas, para mim, não bastava adicionar em meus projetos uma biblioteca que fizesse isso. Eu queria ver o que de fato acontecia “debaixo dos panos” dentro de uma função capaz de clonar grandes estruturas de dados. O grande físico Richard Feynman dizia: “Aquilo que eu não posso criar, não consigo entender”.
Essa busca me mostrou alguns conceitos-chave, que nos levarão a um novo patamar como programadores e que apresentarei ao longo deste artigo: como o Javascript armazena dados em memória? Como construir uma função capaz de identificar o tipo de um dado? Por fim, construiremos uma função utilizando Javascript puro, capaz de produzir clones imutáveis.
Vamos aos primeiros conceitos-chave?!
Para começar: existem diversas maneiras de se clonar uma estrutura de dados, como arrays e objetos. Entretanto, há dois tipos de clonagens:
- Uma clonagem superficial, também chamada de Shallow Clone, que copia somente a superfície de uma estrutura alvo para um outro endereço de memória e mantém suas propriedades, apontando para o mesmo endereço de memória da estrutura original. Qualquer alteração nas propriedades internas de um Shallow Clone afetará a estrutura original, e vice-versa.
- Temos também a clonagem profunda, chamada Deep Clone, que realiza uma cópia da estrutura alvo e de todas as suas propriedades internas para novos endereços de memória. Isto é, o Deep Clone gera uma nova estrutura idêntica e desconectada da estrutura original, em que qualquer alteração nesta estrutura não refletirá na estrutura original.
Cada uma dessas técnicas de clonagem “brilha” em contextos diferentes. Quando trabalhamos com estruturas constituídas de tipos primitivos, não há necessidade de criarmos mecanismos complexos e custosos para clonagem, podemos seguir com a técnica de Shallow Clone. Porém, ao trabalharmos com estruturas de dados complexas e aninhadas, o Deep Clone é a melhor alternativa.
Ao longo deste artigo, serão apresentadas as motivações para utilizar a técnica de Deep Clone e, como bônus, vamos implementar uma técnica de imutabilidade para garantirmos que nossos dados não poderão ser alterados. Então, vamos lá!
Como os tipos de dados do Javascript são armazenados em memória
Sabemos que o Javascript possui dois grupos de tipos de dados: os tipos primitivos e os tipos não primitivos, compostos por: Boolean, Null, Undefined, BigInt, String, Number e Symbol.
Os tipos primitivos são imutáveis por natureza. Ao realizar qualquer alteração em um tipo primitivo, o próprio interpretador do Javascript, em tempo de execução, se encarregará de alocar um novo endereço de memória para o resultado transformado:

Quando a variável num1 foi criada, o interpretador do Javascript criou um identificador único para ela. Alocou um endereço na memória (por exemplo, EJ0001), e armazenou o valor “1” no endereço alocado.
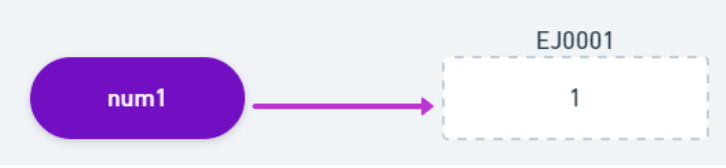
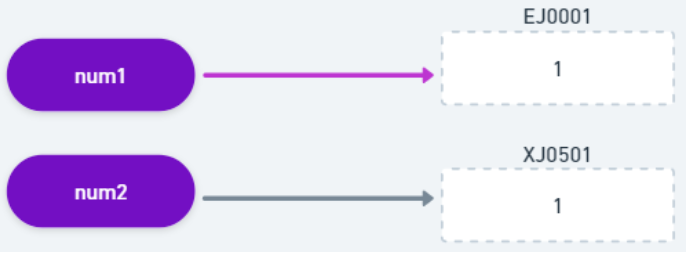
Quando definimos que num2 é igual a num1, o que o Javascript fez “por debaixo dos panos” foi:
- Definiu um identificador único para a variável: num2;
- Alocou um novo endereço de memória (ex: XJ0501);
- Copiou o valor “0”, do endereço de memória EJ0001 da variável num1, para o endereço XJ0501;
- Apontou o identificador num2 para este novo endereço de memória (ex: XJ0501).
Isso significa que, ao definir uma variável igual a outra, cada variável terá sua própria cópia do dado armazenado. Isso ocorre porque haverá dois lugares diferentes de armazenamento para cada variável. Essa é a natureza imutável dos tipos primitivos.
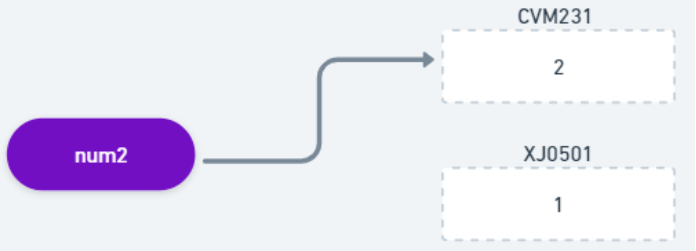
Na linha 3, quando incrementamos o valor da variável num2, o Javascript alocou uma nova unidade de memória (por exemplo: CVM231), armazenou o valor da expressão “num2++” e apontou o identificador da variável num2 para esse novo endereço de memória.
Esse comportamento é diferente se for realizado com objetos e arrays, considerados tipos não primitivos. Essas estruturas de dados são armazenadas em outra região dentro da arquitetura da linguagem, chamada Heap, capaz de armazenar dados não ordenados que podem crescer e diminuir dinamicamente como objetos e arrays.
Quando declaramos uma variável “person” e atribuímos a ela um tipo não primitivo como um objeto vazio:

É isso que acontece “debaixo dos panos”:
- Um identificador é criado com o nome “person”;
- Um endereço de memória é alocado em tempo de execução na Stack (ex: CM9323);
- É armazenado, no endereço criado na Stack, uma referência para um endereço de memória alocado na Heap;
- O endereço de memória na Heap armazenará o valor que foi atribuído à “person”; neste caso, um objeto vazio.
A partir desse ponto, qualquer alteração que fizermos no objeto person acontecerá na Heap, e todas as variáveis que apontam para o mesmo endereço de memória de person serão afetadas pela mudança.

Esse é o comportamento nativo do Javascript ao lidar com a memória. Mas por que ele se comporta desse jeito? Justamente para economizar memória e ganharmos em performance.
Imagine um cenário hipotético onde temos um simples array com 1 milhão de itens. Se copiarmos este array 10 vezes, teremos 10 arrays distintamente desconectados com 1 milhão de itens cada, totalizando em 10 milhões de itens, sendo que 9 milhões destes são cópias idênticas do primeiro array.
Mas, em certos casos, principalmente quando trabalhamos seguindo o princípio da imutabilidade, um dos pilares do paradigma funcional, queremos ter um comportamento diferente. Gostaríamos de copiar todos os valores contidos dentro de endereços de memória para novos endereços de memória. Essa prática nos livra do efeito colateral presente na concorrência de acesso a dados: se dois locais distintos da aplicação concorrem para acessar e subscrever um mesmo recurso no mesmo instante de tempo, um dos locais que espera receber uma “bola” pode obter um “quadrado” devido a atualização que o outro local fez anteriormente.
Construindo uma função de checagem de tipos
Para iniciar nosso exemplo, desenvolveremos uma função capaz de checar o tipo de qualquer variável que passamos para ela e retornar seu tipo em formato de string em caixa baixa. Essa função nos ajudará a testar o tipo de nossas estruturas arrays e objetos, além de enriquecer seu repertório de programador:

Basicamente, nossa função typeCheck recebe um valor e, em cima deste valor, executamos a chamada do método toString, presente no prototype dos objetos com auxílio da API Reflect, que nos assegura a devida execução de toString. O seu retorno será uma string envolvida por colchetes, como a seguinte representação: [object String]. Por fim, com o auxílio das funções slice, indexOf e toLowerCase, presentes nas strings, podemos manipular nosso resultado e devolver uma string que representa o valor passado como parâmetro em nossa função.
Normalmente, alguém me perguntaria: por que você não usa o operador typeof do próprio Javascript ao invés de criar uma função como essa?
O typeof não sabe diferenciar um null de um object.
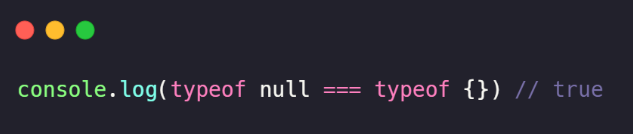
O resultado de nossa função para diferentes tipos:
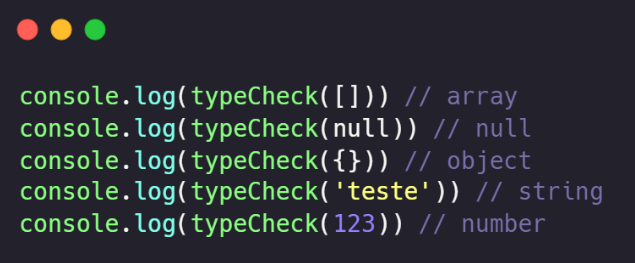
Construindo uma função de clonagem profunda de arrays
Para construirmos uma função que clona profundamente uma estrutura de array, precisamos adentrar em cada posição e testá-la. Se cada posição do array for um array, adentre neste e teste-o, e assim recursivamente, até chegar na condição de parada. No nosso caso, em qualquer valor diferente de um array.

O resultado é uma função bonita, estruturada e imperativa. Vamos fazer um ajuste simples, tornando-a ainda mais enxuta e declarativa, nos beneficiando da magia da programação funcional, testando e comparando o resultado de nossa função cloneArray.

Observe que, abaixo, temos dois exemplos: no primeiro, apontamos numbersCopy para o mesmo endereço de memória de numbers, portanto, a saída no console na linha 3 é “true“. Porém, na linha 4, nossa função entra em ação, clonando o array numbers para outra posição na memória, por isso, o resultado é “false”.
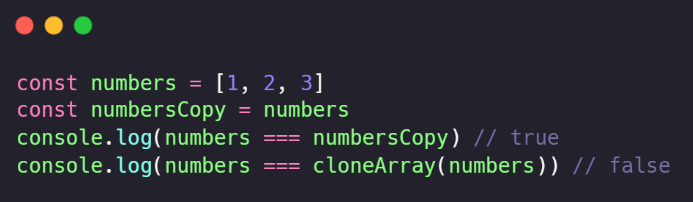
Construindo uma função de clonagem profunda de objetos
Seguindo o mesmo raciocínio de nossa função cloneArray, vamos construir a cloneObject. Seu objetivo será percorrer as propriedades de um objeto e copiá-las para um novo objeto. Para isso, vamos utilizar novamente a técnica de recursividade, pois não temos um limite pré-definido de profundidade. Enquanto houver uma propriedade que seja do tipo “object”, entre nela e percorra-a, também retornando um novo objeto.

Primeiro passo: dentro de nossa função cloneObject, devemos testar o tipo de dado recebido por argumento; no caso, a variável “element”. Se o tipo de element for diferente de “object”, return element. Senão, prossiga para o restante da implementação.
A partir dessa etapa, na linha 3, precisamos retornar um novo “objeto” que conterá uma cópia das propriedades de “element”. Há diversas formas de realizar essa implementação, mas optei pela abordagem declarativa para nos aprofundarmos um pouco mais nas maravilhas do universo do paradigma funcional.
A função construtora de objetos “Object” possui um método estático chamado fromEntries. Esse método retorna um novo objeto a partir de uma estrutura de dados que se assemelha a um array bidimensional: [‘chave’, ‘valor’] ]. Ex.:

Partindo desse ponto, podemos obter todas as chaves de propriedades de element por meio de um array com o método “Object.keys” e, em cima desse array, mapear um novo array bidimensional, onde cada valor de propriedade será passado recursivamente para a função “cloneObject”:

Na linha 4, obteremos um array contendo todas as chaves das propriedades do objeto “element“. Por meio do método “map“, vamos percorrer cada posição desse array retornando um novo array, onde o valor da respectiva propriedade de “element” que está sendo iterada será passado para dentro de cloneObject recursivamente. Se esse valor não for do tipo “object“, retorne-o. Senão, itere por suas propriedades e teste-as. Testando nossa função, obteremos o seguinte resultado ao clonar um objeto:
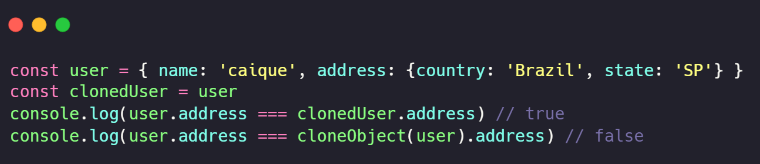
Observe que, na linha 3, estamos comparando a propriedade address, um objeto aninhado dentro de user, com a propriedade address de clonedUser. Como ambos apontam para o mesmo endereço de memória, o resultado é “true”. Na linha 4, colocamos cloneObject em ação e fizemos a mesma comparação. Dessa vez, obtivemos “false”, pois o novo objeto gerado com suas propriedades está apontando para outro endereço de memória.
Construindo a função deepClone
Agora, temos nossas funções de clonagem de array e de objeto. Tudo que precisamos fazer é uni-las em nossa orquestra. Para isso, criaremos uma função que será responsável por decidir qual clonagem será executada de acordo com o dado informado:

A deepClone avaliará o element: se ele for do tipo array, execute o cloneArray; se for do tipo object, execute o cloneObject. Caso não entre em nenhuma dessas condições, apenas retorne seu valor original.
Agora, precisamos fazer um ajuste em cada uma de nossas funções de clonagem para que elas chamem o deepClone recursivamente:

Em cloneArray, alteramos o callback de map para deepClone.

Em cloneObject, alteramos a linha 5: onde estava cloneObject, colocamos deepClone. Fazendo um teste final, teremos uma estrutura de dados do tipo object, com um array interno, ambos apontando para diferentes endereços de memória em relação ao endereço do objeto original “person“.
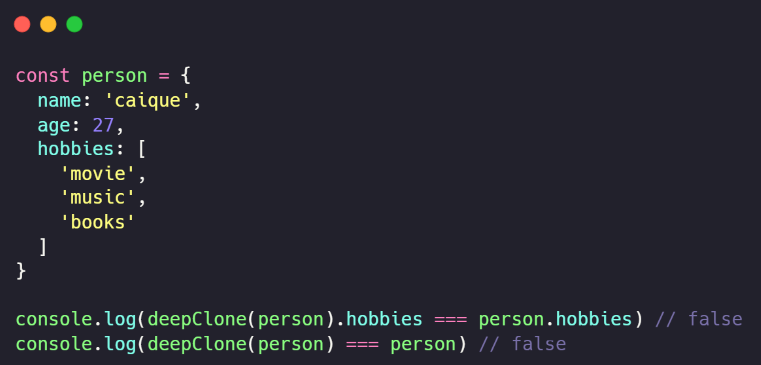
Recapitulando o que fizemos:
1 – Aprendemos quais são os tipos primitivos e não primitivos do Javascript;
2 – Aprendemos como são alocadas em memória as variáveis primitivas e não primitivas;
3 – Implementamos uma função capaz de identificar o tipo de dado passado para ela e retornar seu valor em string;
4 – Vimos dois tipos de paradigmas: funcional e estruturado para implementar a função cloneArray;
5 – Criamos a função cloneObject e vimos como funciona o método Object.fromEntries.
Bônus: tornando nossos dados imutáveis
A partir desse ponto, somos capazes de clonar qualquer estrutura de objeto e array, mas, ainda assim, não escapamos do comportamento natural do Javascript, em que alteramos um dado dentro de um tipo não primitivo e essa alteração se reflete em todas as variáveis que apontam para a mesma referência.
Nossas estruturas clonadas são mutáveis:
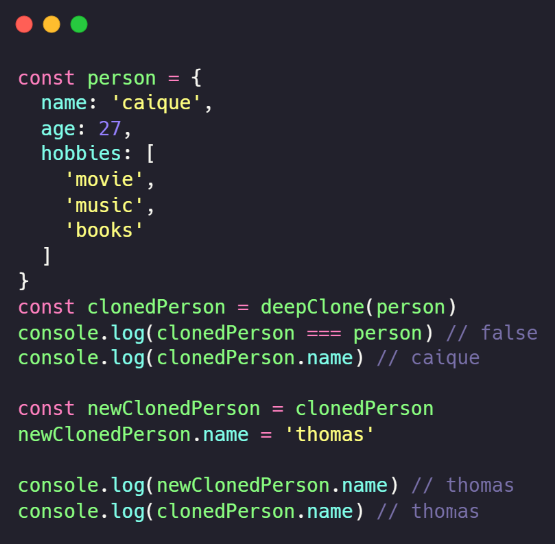
Porém, podemos resolver esse efeito com uma simples função:
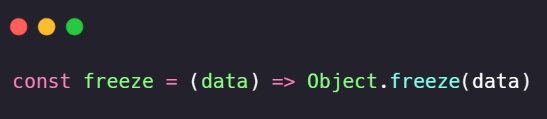
A função construtora Object em Javascript disponibiliza um método estático capaz de congelar objetos. Esse congelamento impede qualquer alteração, inserção ou remoção de dados dentro da estrutura congelada. Entretanto, esse congelamento é realizado em nível superficial.
Isso significa que a estrutura de dados interna do objeto congelado não será congelada, e a mesma estará suscetível a mudanças. Para resolvermos isso, teremos que partir para a recursão novamente; a boa notícia é que já deixamos o terreno pronto anteriormente. Faremos uma simples mudança em nossa função deepClone:
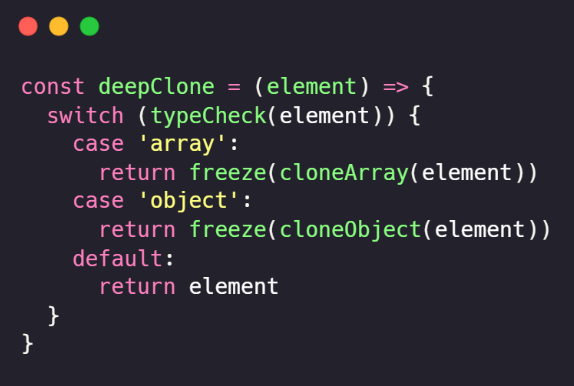
Nas linhas 4 e 6, adicionamos a chamada para a função freeze, que será chamada recursivamente por meio das chamadas de deepClone. Nosso resultado final sobre o exemplo anterior será:
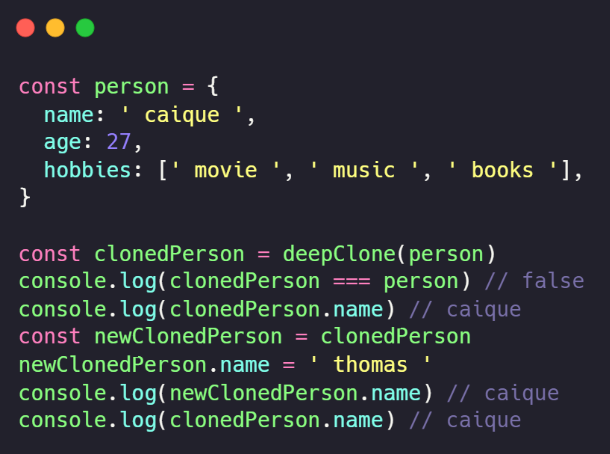
Como podemos observar, as estruturas person e clonedPerson, apesar de possuírem os mesmos valores, apontam para endereços de memória diferentes. E a respeito da estrutura resultante (clonedPerson), se tentarmos sobrescrever alguma de suas propriedades, a mudança não acontecerá, já que nossa estrutura é imutável.
Conclusão
Ao longo deste artigo, exploramos um território que nos abre portas para uma série de questões a respeito de como o Javascript funciona por “debaixo dos panos”. Essas questões formam a bússola que aponta para o norte, onde encontram-se os melhores programadores.
Além disso, aplicamos técnicas de programação funcional, através das quais mudamos uma instrução imperativa para uma abordagem declarativa. Conhecemos uma função capaz de retornar o tipo de qualquer dado passado para ela, a typeCheck, e espero que a guarde com carinho e faça bom uso.
E, para finalizar, deixo aqui um desafio. No início do artigo, comentei que é possível clonar estruturas de dados como arrays e objetos, e omiti intencionalmente outras estruturas nativas do Javascript, como Sets, Maps, WeakMaps e WeakSets. Como implementar funções de clonagem para essas estruturas? Sua nova missão, caso decida aceitar, é encontrar essas respostas.
Há um tempo atrás, encontrei essas respostas e desenvolvi uma biblioteca especializada em clonagem de estruturas, a Simple Immuter.
Referências



