Introdução ao estudo e seus objetivos
A integração da inteligência artificial (IA) no ecossistema de programação revolucionou a área, resultando em avanços particularmente significativos na tradução de códigos. O objetivo deste artigo é discutir uma série de estudos anteriores e analisar os resultados obtidos diretamente desses estudos fundamentais.
É importante ressaltar que as conclusões aqui apresentadas não se limitam a uma simples compilação desses achados, elas representam uma fusão entre os dados extraídos dos estudos citados e as pesquisas originais realizadas pelos autores. Esta abordagem produz uma síntese rica que combina o conhecimento existente com novas perspectivas e faz uma contribuição significativa para o campo da tradução de código assistida por IA.
Para a realização das pesquisas, foram selecionados modelos de linguagem de grande escala (LLMs) que demonstraram maior potencial na tarefa de conversão de código. O propósito dessa escolha foi responder às principais questões de pesquisa (RQs), explorando a eficácia dos LLMs na tradução de código, compreender a natureza dos erros de tradução e investigar soluções potenciais para atenuar essas dificuldades.
A tradução de código visa converter o código-fonte de uma linguagem de programação (LP) para outra. Dadas as promissoras habilidades dos grandes modelos de linguagem (LLMs) em síntese de código, pesquisadores estão explorando ativamente o potencial deles para automatizar a tradução de código.
Compreender as limitações dos LLMs é essencial para avançar o estado da tradução de código baseada em LLM. Para tanto, existem estudos em larga escala para investigar a capacidade dos LLMs, incluindo LLMs gerais e LLMs de código, na tradução de código entre pares de diferentes linguagens, incluindo C, C++, Go, Java e Python.
LLMs Gerais
Os LLMs Gerais são modelos pré-treinados em vastos conjuntos de dados textuais, que abrangem tanto linguagem natural quanto código de programação. Eles são projetados para serem aplicados em uma ampla gama de tarefas. Os estudos e artigos referenciados focaram nos LLMs gerais mais avançados, com capacidade de até 20 bilhões de parâmetros, conforme listados na Tabela de Liderança de LLMs Abertos do Hugging Face, incluindo modelos como GPT-4, Llama2, TB-Airoboros e TB-Vicuna. Estes representam uma seleção diversificada de modelos de IA altamente versáteis.
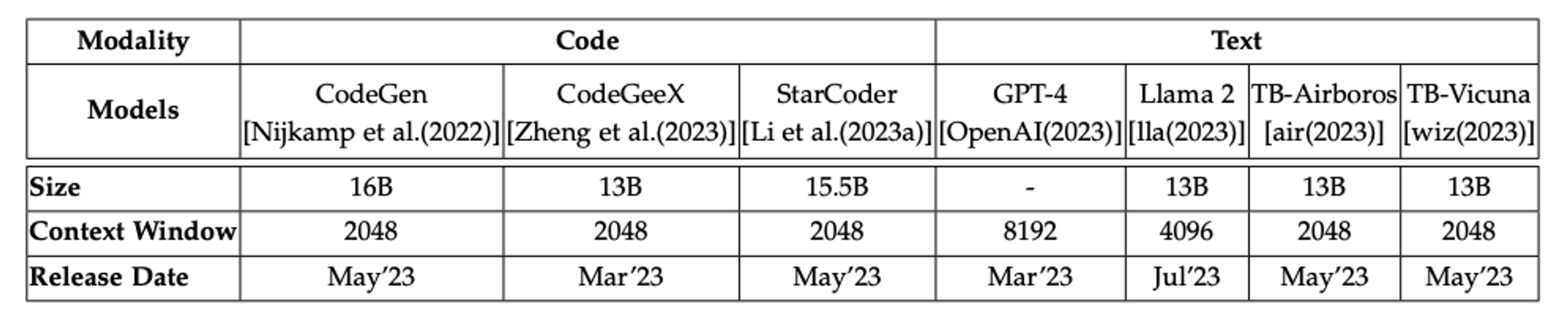
Detalhamento dos LLM`s abordados neste artigo, e nos artigos relacionados.
LLMs de Código
Os LLMs de código são desenvolvidos com um propósito específico: facilitar e automatizar tarefas diretamente associadas à programação. Os estudos e artigos mencionados focaram nos três LLMs de código mais inovadores e recentemente lançados: CodeGen, StarCoder e CodeGeeX, que representam o que há de mais recente em termos de especialização em IA para tarefas de codificação.
Detalhamento dos LLM`s abordados neste artigo, e nos artigos relacionados.
Eficácia dos LLMs na tradução de código
Exceto pelo GPT-4 e StarCoder, todos os outros modelos tiveram um desempenho insatisfatório.
Existe uma forte correlação entre o número médio de testes por amostra de tradução e a tradução malsucedida (coeficiente de correlação (r) variando de 0,64 a 0,85 para todos os modelos). Ou seja, quanto mais rigoroso for o conjunto de testes existente, melhor ele pode avaliar se uma tradução preserva a funcionalidade.
Foram realizadas neste estudo (https://arxiv.org/pdf/2308.03109.pdf) 43.379 traduções em todos os LLMs listados, medindo o sucesso contra os testes fornecidos com as amostras de código.
O estudo também destacou um contraste acentuado no desempenho do LLM entre projetos do mundo real e benchmarks elaborados. O GPT-4 gerenciou uma taxa de sucesso de 8,1% em projetos do mundo real, enquanto os outros modelos não obtiveram sucesso algum.
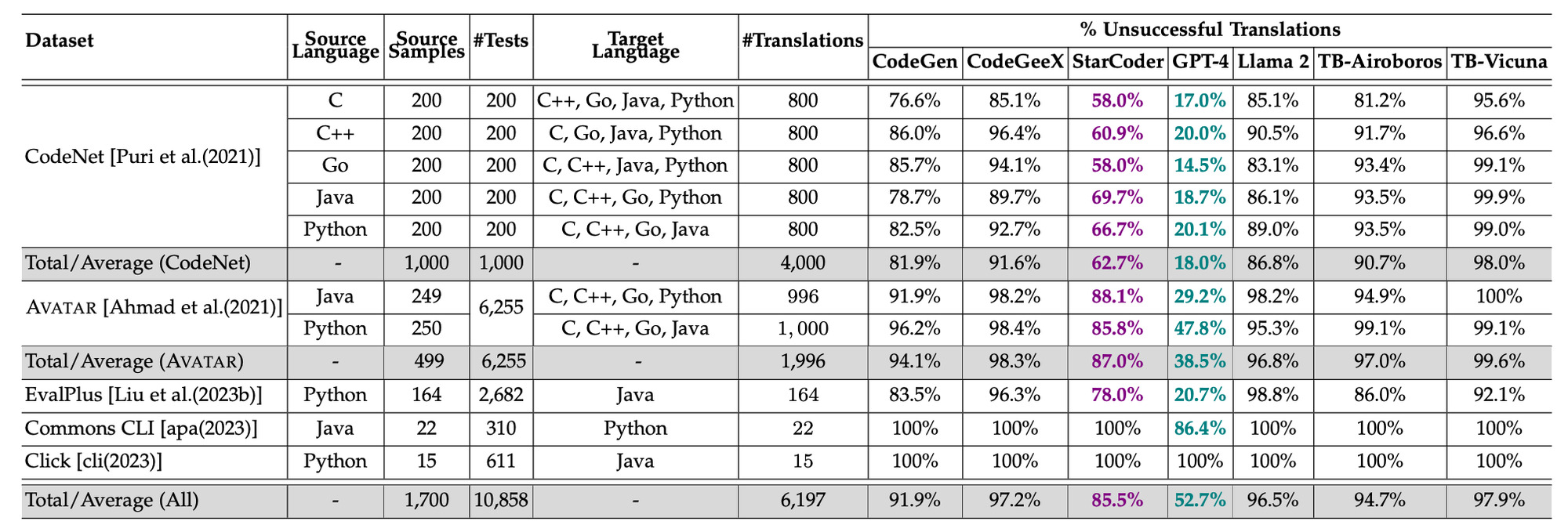
Taxa de insucesso %
Um dos desafios frequentemente encontrados na tradução de código, assim como em outras tarefas que envolvem LLMs, é a limitação da janela de contexto. Um estudo detalhado (disponível aqui) investigou o impacto de contextos de entrada mais amplos no desempenho dos modelos de linguagem.
Observou-se uma degradação notável na eficácia deles quando informações cruciais são reposicionadas, revelando a luta dos modelos em manejar efetivamente informações em tais amplitudes de dados. A questão se agrava especialmente quando informações vitais são situadas ao centro de um contexto extenso. Este fenômeno sublinha que simplesmente estender o contexto de entrada não é suficiente para contornar essas limitações de processamento da LLM.
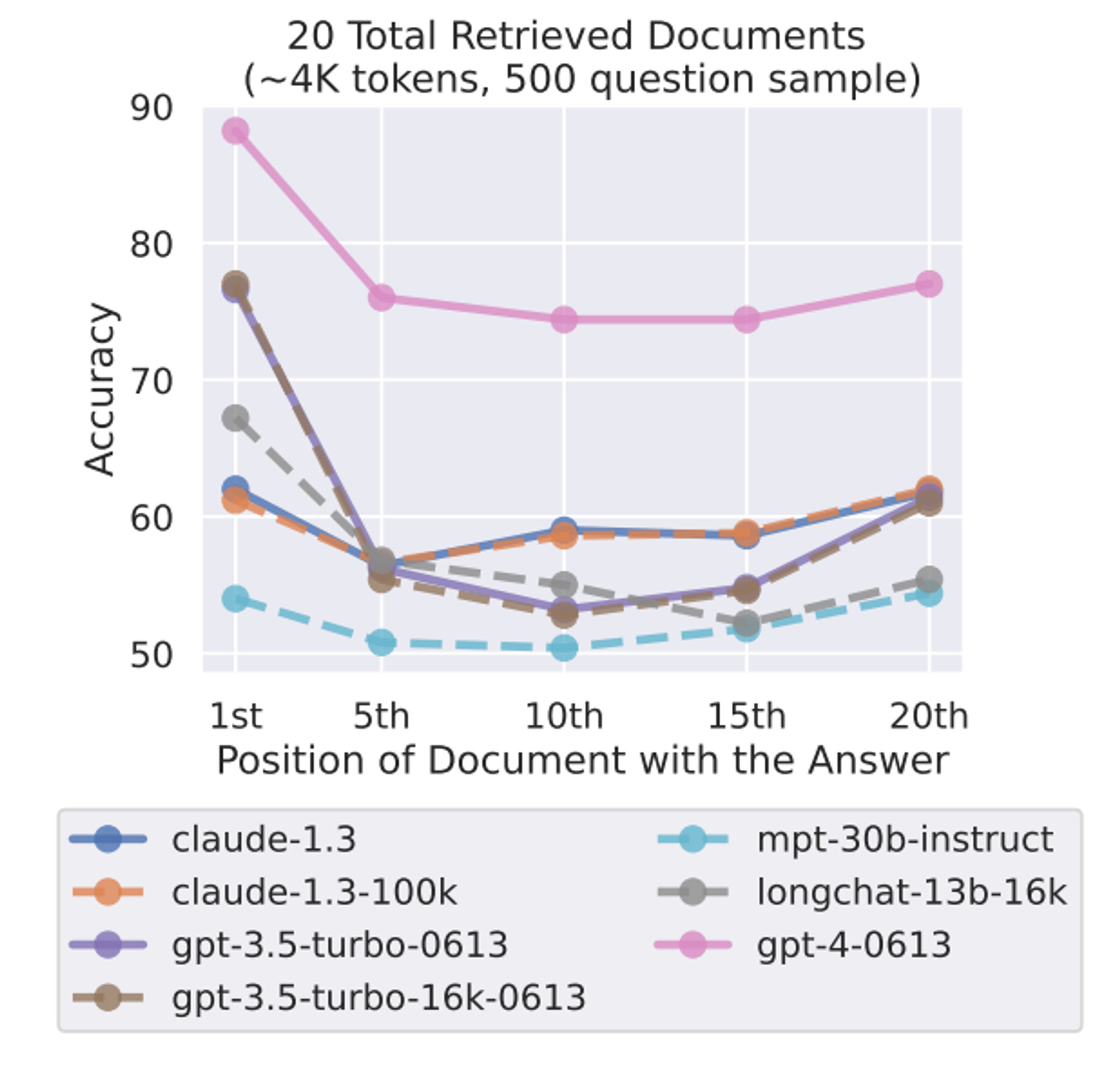
Embora o GPT-4 apresente um desempenho absoluto superior em comparação com outros modelos, seu desempenho ainda se degrada quando as informações relevantes estão localizadas na parte central do contexto de entrada.
Compreensão dos Bugs em Traduções de Código Baseadas em LLM
A maioria dos LLMs luta com tarefas de tradução de código, mostrando sucesso limitado mesmo com benchmarks elaborados e desempenhando-se ainda pior com projetos do mundo real.
Na figura abaixo, apresentam-se os resultados deste experimento para cada modelo, acumulados para todas as LPs (Language Program).
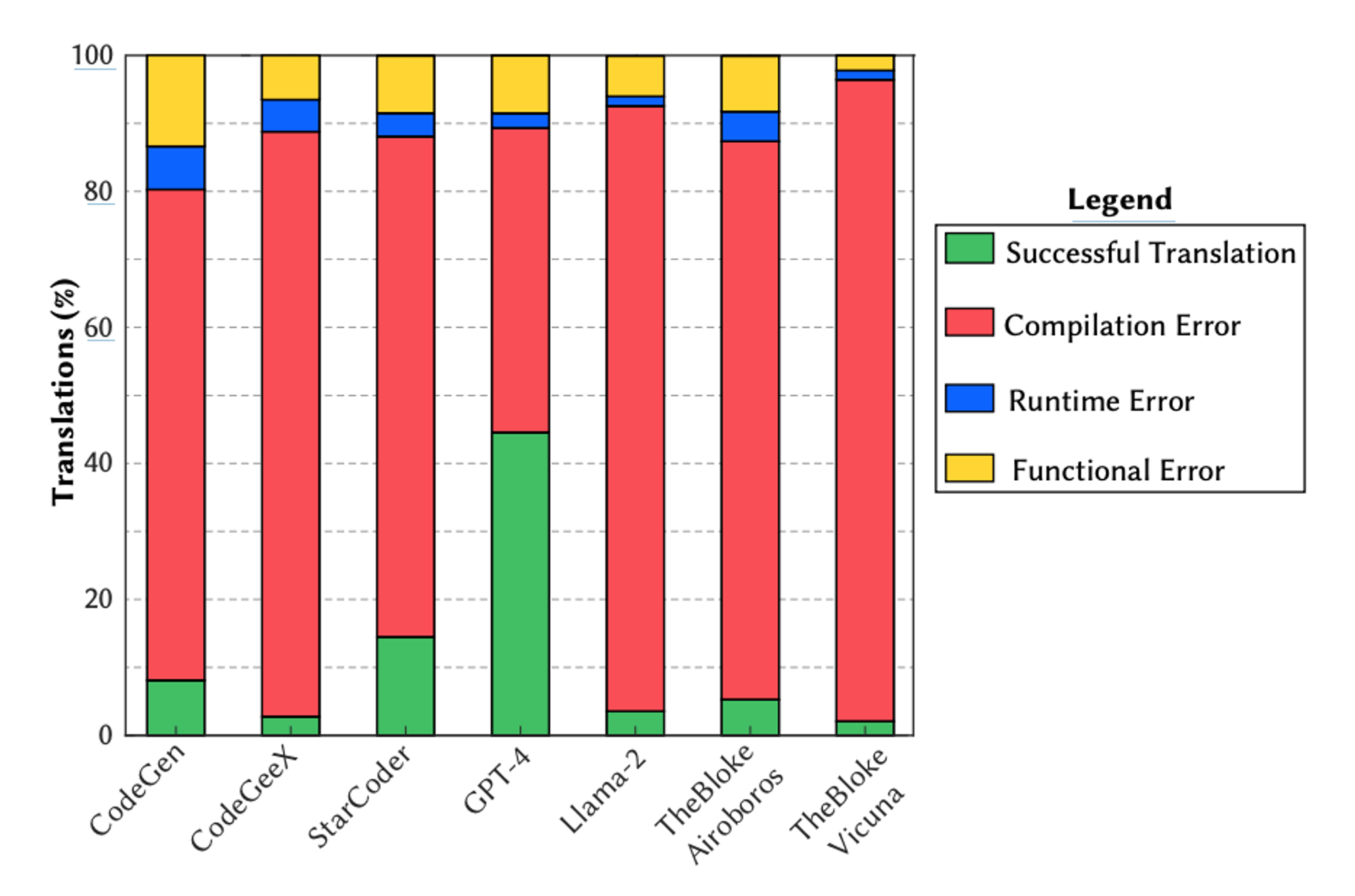
A partir desses resultados, observamos que a maioria das traduções malsucedidas resulta em erros de compilação (77.8%), indicando que tanto os LLMs gerais quanto os de código têm dificuldade em compreender a sintaxe do código.
O segundo efeito mais comum, o Erro Funcional (Functional Error), demonstra que o código está sintaticamente correto e executa sem exceção, mas não mantém a funcionalidade implementada na linguagem origem.
Os resultados destacam também vários desafios chaves na tradução de código impulsionada por IA:
1. Análise de Entrada (Input Parsing): uma parcela significativa de bugs (18,1%) surge da incapacidade dos LLMs de analisar precisamente as entradas.
2. Seleção de Tipos de Dados (Data Type Selection): escolher corretamente os tipos de dados na linguagem alvo é crítico e representa 11,5% de todos os bugs.
3. Replicação de Sintaxe (Syntax Replication): LLMs podem replicar de forma inadequada a sintaxe da linguagem de origem, levando a erros em 2,4% dos casos.
4. Lacunas Sintáticas e Semânticas (Syntactic and Semantic Gaps): cerca de 30,5% dos bugs são devido a incompatibilidades entre as linguagens de origem e alvo, com 24,3% de todos os bugs causados por violação dos requisitos da linguagem alvo (paradigmas de linguagem).
5. Erros Lógicos e de Dependência (Logical and Dependency Errors): problemas com a lógica do código e dependências ausentes, particularmente importações, compõem 24,2% dos bugs.
6. Tradução de Chamadas de API (API Call Translation): substituir chamadas de API entre linguagens pode introduzir bugs, indicando a complexidade de encontrar APIs equivalentes.
7. Complexidade do Mundo Real (Real-World Complexity): códigos do mundo real apresentam desafios adicionais de tradução, como o manuseio de recursos avançados como sobrecarga de métodos e anotações, que não estão presentes em benchmarks.
8. Características da Linguagem (Language Characteristics): a taxa de sucesso da tradução é fortemente influenciada pelas características específicas das linguagens de origem e alvo, como sistemas de tipos e suporte a metaprogramação.
Estes achados sublinham a complexidade da tradução de código e a necessidade de os LLMs compreenderem melhor tanto as nuances sintáticas quanto semânticas de diferentes linguagens de programação para aprimorar a precisão da tradução.
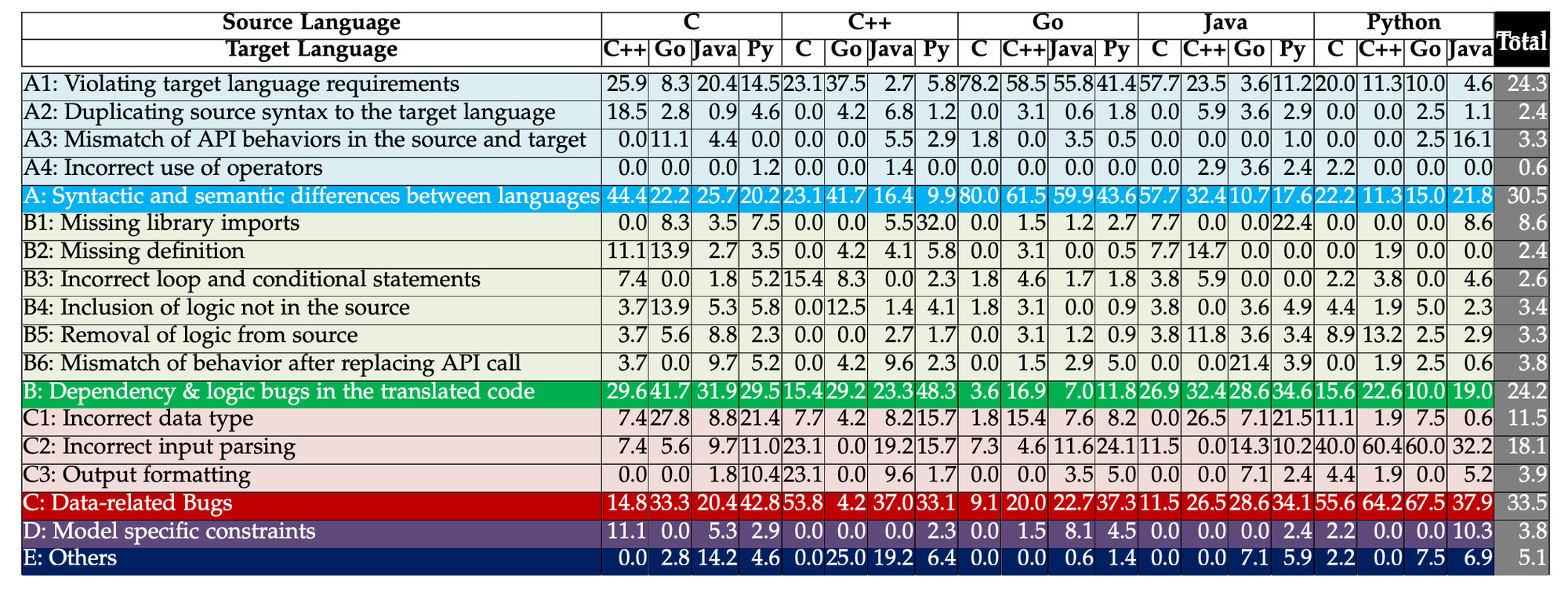
Tipos de bugs introduzidos durante a traducão de código. Todos os valores estão em %
Potencial soluções para atenuar desafios e dificuldades
Existe um amplo espaço para o aprimoramento dos LLMs de código aberto e fechado na tradução de código. Para modelos de código fechado (por exemplo, GPT-4), a crescente complexidade dos casos de uso (projetos do mundo real) exige uma evolução nas estratégias de prompting (o ato de fornecer a um modelo de linguagem um texto de entrada que o orienta a produzir um tipo específico de resposta).
Uma direção de pesquisa promissora pode envolver a criação de prompts que se constroem mutuamente, seguindo um fluxo coerente e lógico de informações, que podem incluir informações auxiliares relevantes, como declarações de variáveis ou assinaturas de funções, para manter a integridade e consistência após a tradução.
Para LLMs de código aberto, melhorar o desempenho pode envolver o fine-tuning, no qual diferentes modelos especializados são cuidadosamente treinados para abordar aspectos distintos do processo de tradução (particularmente aqueles relacionados às categorias de bugs examinadas neste artigo). Uma compreensão mais abrangente poderia ser alcançada ao aproveitar o poder de LLMs precisos e finamente ajustados, cada um focado em um subconjunto único dos desafios inerentes à tradução de código.
Conclusão
Embora os modelos de linguagem de grande escala (LLMs) contemporâneos – englobando tanto plataformas de uso geral quanto aquelas especializadas em código – enfrentem desafios substanciais na automatização da tradução de código (especialmente diante das complexidades inerentes aos projetos de software do mundo real), eles ainda não atingiram um nível de eficácia que permita a conversão de código de maneira fidedigna e com a qualidade exigida pelo ambiente corporativo.
No entanto, à medida que avanços contínuos nos modelos de deep learning são realizados, há expectativas de que, em um futuro próximo, as capacidades dos LLMs serão aprimoradas para superar as atuais barreiras, proporcionando uma conversão de código mais robusta, precisa e economicamente viável.
A necessidade de pesquisas adicionais é evidente e o potencial de crescimento nessa área sugere mudanças significativas que podem transformar as práticas de desenvolvimento de software.
Para uma exploração aprofundada dessas percepções, por favor consulte o artigo abrangente disponível em: Understanding the Limitations of AI in Code Translation.
Artigos relacionados:
- “How Do Language Models Use Context? Empirical Studies on Long-Context Abilities” (arXiv:2307.03172): este estudo empírico investiga como modelos de linguagem como GPT-4 processam e utilizam contextos de entrada longos. Por meio de experimentos controlados, os pesquisadores demonstram que o desempenho desses modelos é comprometido quando informações relevantes aparecem no meio do contexto de entrada.
- “Evaluating Large Language Models Trained on Code” (arXiv:2212.10496): este trabalho oferece uma avaliação de modelos de linguagem de grande escala que foram treinados em dados de código. A pesquisa explora suas capacidades de compreensão e geração de código, trazendo insights sobre como esses modelos podem ser usados no desenvolvimento de software.
- “Challenges in Generalization in Open Domain Question Answering” (arXiv:2211.01910): este paper discute os desafios enfrentados por sistemas de resposta a perguntas de domínio aberto, incluindo a questão de como os modelos de linguagem acessam e integram informação de seus contextos de entrada em suas operações de geração de texto e resposta.
- “CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning” (arXiv:2212.10496): este artigo apresenta o CodeRL, uma abordagem que combina modelos de linguagem pré-treinados com aprendizado por reforço profundo para gerar código. A pesquisa explora como essa metodologia pode aprimorar a capacidade dos modelos de linguagem de gerar código funcional e correto, abordando os desafios de generalização e compreensão em tarefas complexas de programação.
Efficiency of AI in Code Translation (Last Version)
*As opiniões aqui colocadas refletem minha opinião pessoal e não necessariamente a opinião da Compass UOL.



